JVM理解
Time: 2024-10-21 Monday 08:42:01
Author: Jackasher
JVM理解
我们常说的栈呀,堆呀,方法区,其实就是java运行时,划分的几块物理空间来存储数据, 每个区域存储的数据不一样,比如栈存的进程,在进程里面存储方法,及其方法变量, 堆里面存对象,方法区里面存类信息
栈存的是方法, 基本数据类型和引用
- 栈内存中存储局部变量和方法调用信息,包括对象的引用(指针)以及原始类型的数据(如 int、char 等)
而堆存储的是实例对象,像是数组,集合等
-
Java 使用堆(Heap)来存储动态分配的对象。堆是一块较大的内存区域,用于存储所有对象实例和数组。
-
当使用 new 关键字创建对象时,这个对象被分配到堆上,并由垃圾收集器管理其生命周期。
-
对象在堆中存活的时间取决于它们的引用是否还存在。堆中的对象不一定会马上被销毁,只有当没有任何引用指向该对象时,垃圾收集器(Garbage Collector)才会标记并清除它。
字符串对象有特殊的存储机制。使用字面量创建的字符串,例如:
1 | |
这个字符串 “Hello” 会存储在字符串常量池中,而不是直接在堆中。
- 常量池存储在堆的特殊区域中,它可以避免创建重复的字符串对象。如果你使用相同的字符串字面量创建多个 String 对象,JVM 会复用常量池中的字符串对象。
方法区存储的是类的元数据
在 Java SE 8 之前,方法区通常被称为永久代(Permanent Generation),而从 Java SE 8 开始,永久代被移除,方法区的实现被称为**元空间(Metaspace)**所以我们可以知道,方法区一定存储的是永久性的信息,
- 例如类的元信息,
- 类的结构信息:包括类名、父类名、接口实现信息、类的修饰符(如 public、abstract 等)。
- 方法信息:类中定义的方法名、修饰符、参数类型、返回值类型等。
- 字段信息:类中定义的所有字段的名称、类型和修饰符。
- 运行时常量池(Runtime Constant Pool)
- *常量池**存储的是编译期间生成的一些常量和符号引用,主要包括:
- 字符串常量
- 基本数据类型的常量
- 方法和字段的符号引用(方法名、字段名、类名等)
- 字符串字面量
- 方法的字节码(Bytecode)
- 方法区还保存类的每个方法的字节码。JVM 在执行方法时,先从方法区中获取该方法的字节码,然后将其解释执行或即时编译为机器码。
- 静态变量
- 静态变量是类级别的变量,所有该类的实例共享这些变量。静态变量在类加载时被分配存储空间,存在于方法区。
- 类的加载信息
- 包括类加载器的信息,类是由哪个类加载器加载的(比如系统类加载器、扩展类加载器等)。
- 编译后的代码(JIT 编译后的本地代码)
- 当 JVM 对某些热点方法进行**即时编译(Just-In-Time compilation, JIT)**时,编译后的本地机器码也可能会存储在方法区中。JIT 编译器会将这些频繁调用的方法转换为机器代码,以加快执行速度。
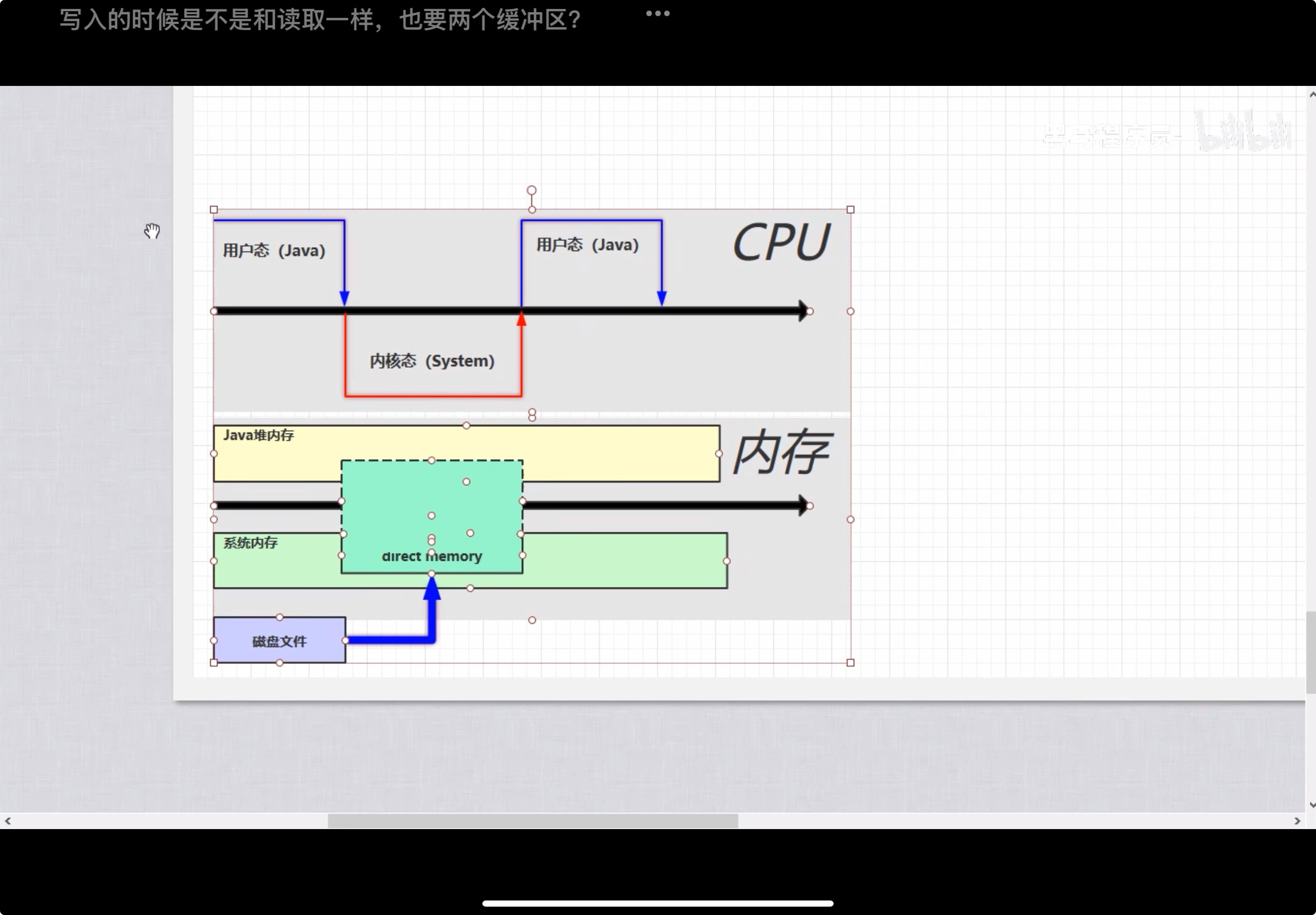
JVM的全景
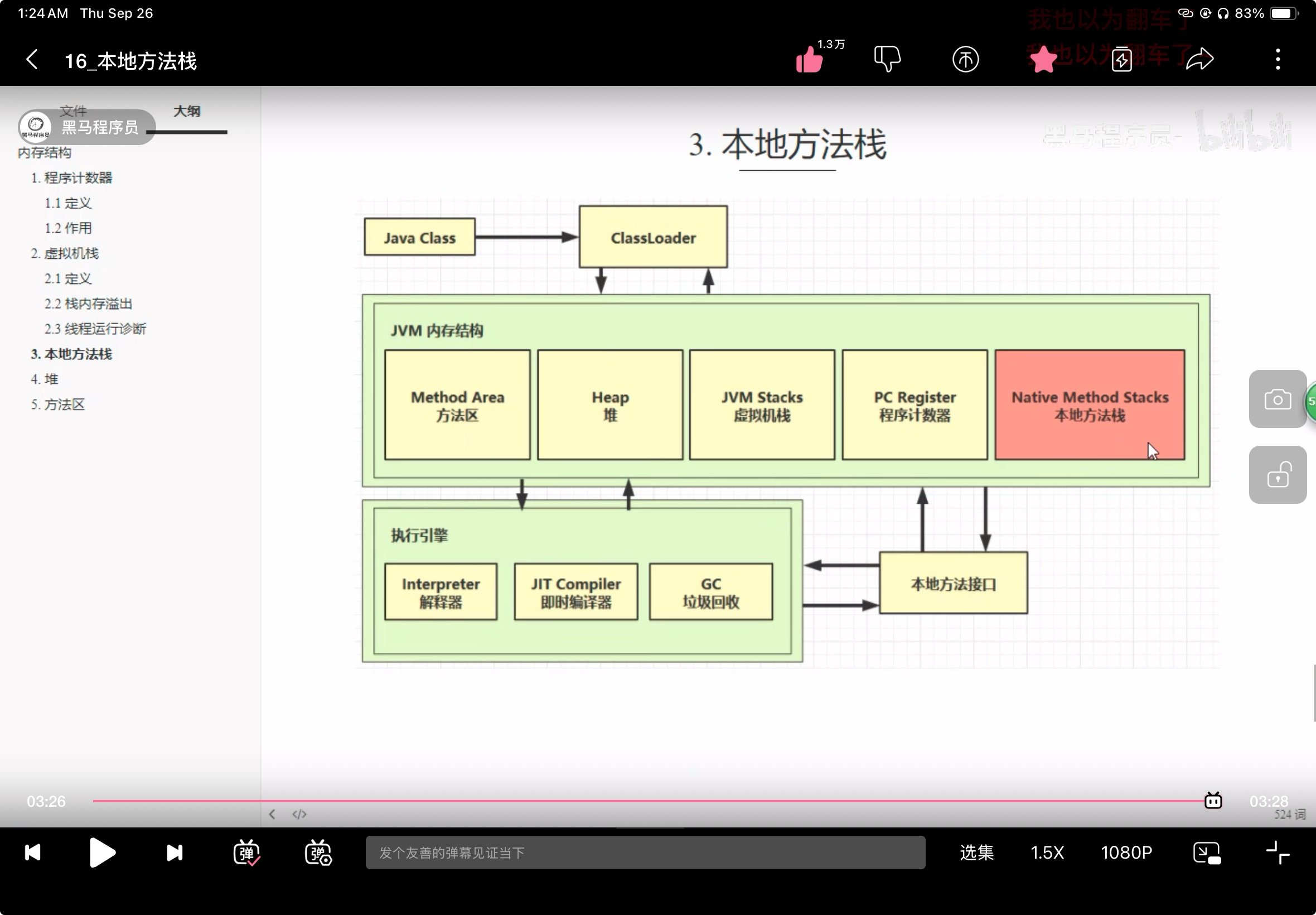
程序计数器
程序计数器,就是指令寄存机,用于存取下一条指令的地址,
栈
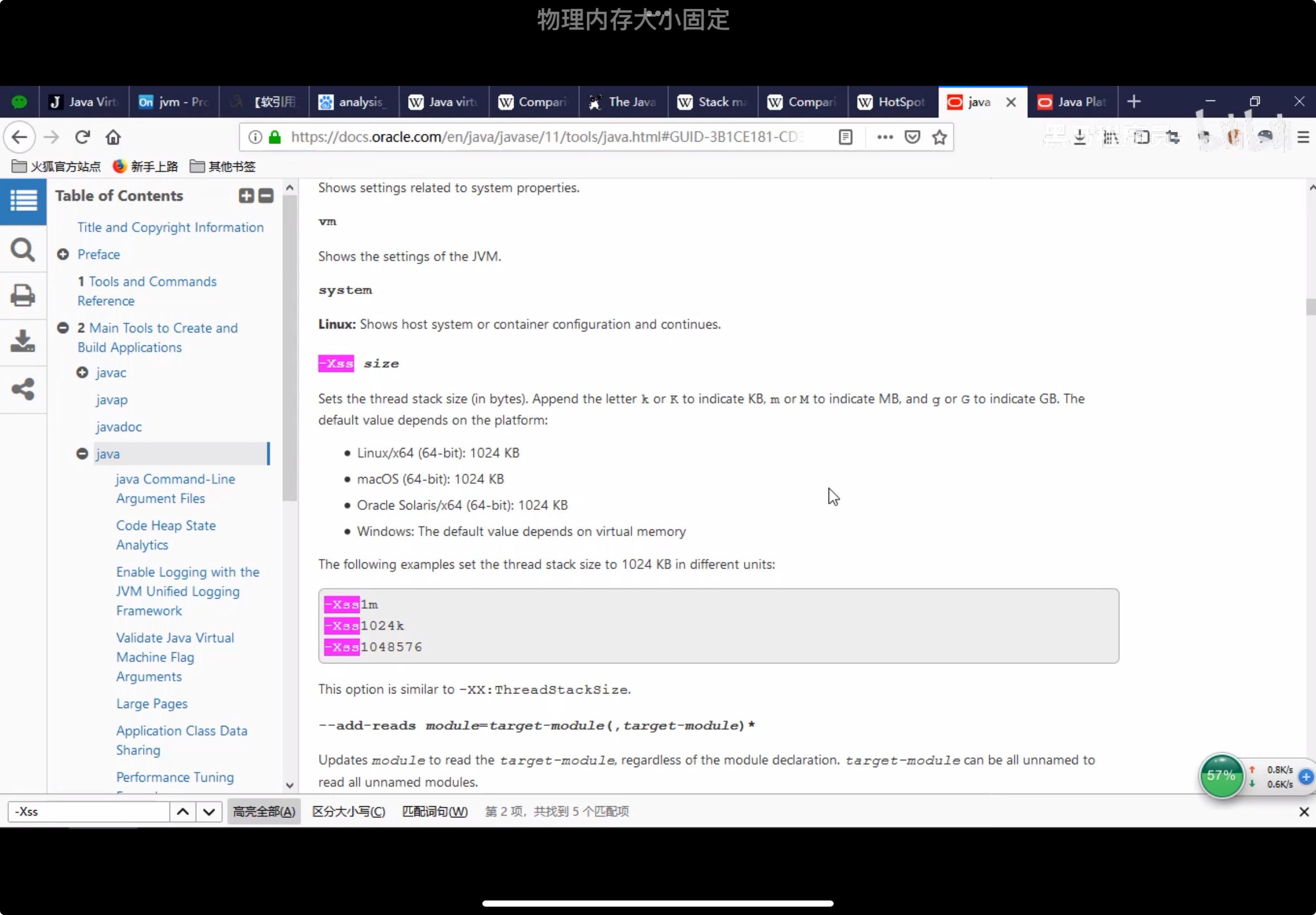
一个线程对应一个栈,一个方法对应一个栈帧, 默认的栈大小是1024kB, -Xss设置栈大小,
垃圾回收不负责栈的回收,栈在方法的执行和消失自动出栈入栈, 如果我们的电脑有500MB,分配的栈是1MB,那么可以生成500个栈, 内存太大,导致栈数量减少,线程数减少, 但是可以增加递归的调用, 局部变量是线程安全的,但是作为方法的参数和返回值时,是不安全的,
栈内存溢出
原因
- 栈帧过多
- 栈帧过大
我们来看着这段代码,栈在45429的时候溢出,

当我们把栈设置为256k时,栈帧数量就被减少到2198
线程诊断
学到一个很有意思的东西, top是用来查看进程的, 而ps是查看线程的
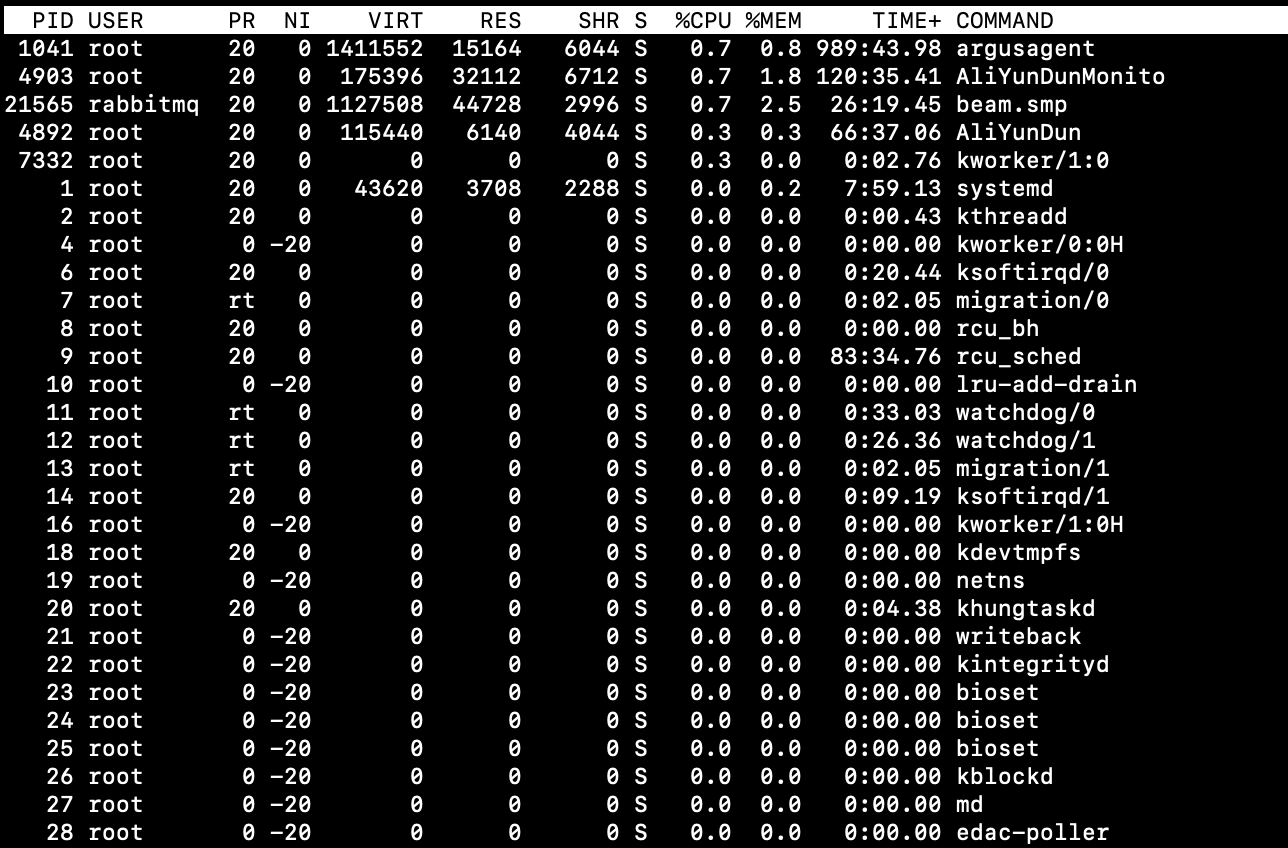
- PID 的全称是 Process ID,它是操作系统分配给每个运行中的进程的唯一标识符。
- TID 的全称是 Thread ID,它是操作系统分配给每个运行中的线程的唯一标识符。在某些系统中,
ps命令可能使用tid来表示线程组ID(Thread Group ID),这与线程ID是不同的概念。 -eo的全称是--output-format,这是一个GNUps命令的选项,允许你指定输出格式。在使用-eo选项时,你可以自定义输出的列,例如pid,tid,%mem,%cpu。
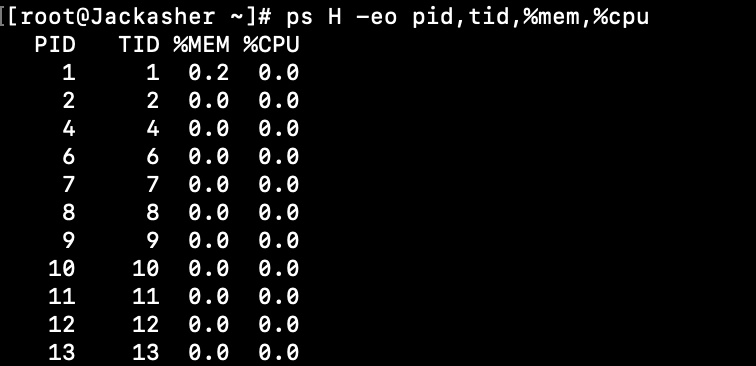
可以看到我的Hexo博客,开了这么多线程
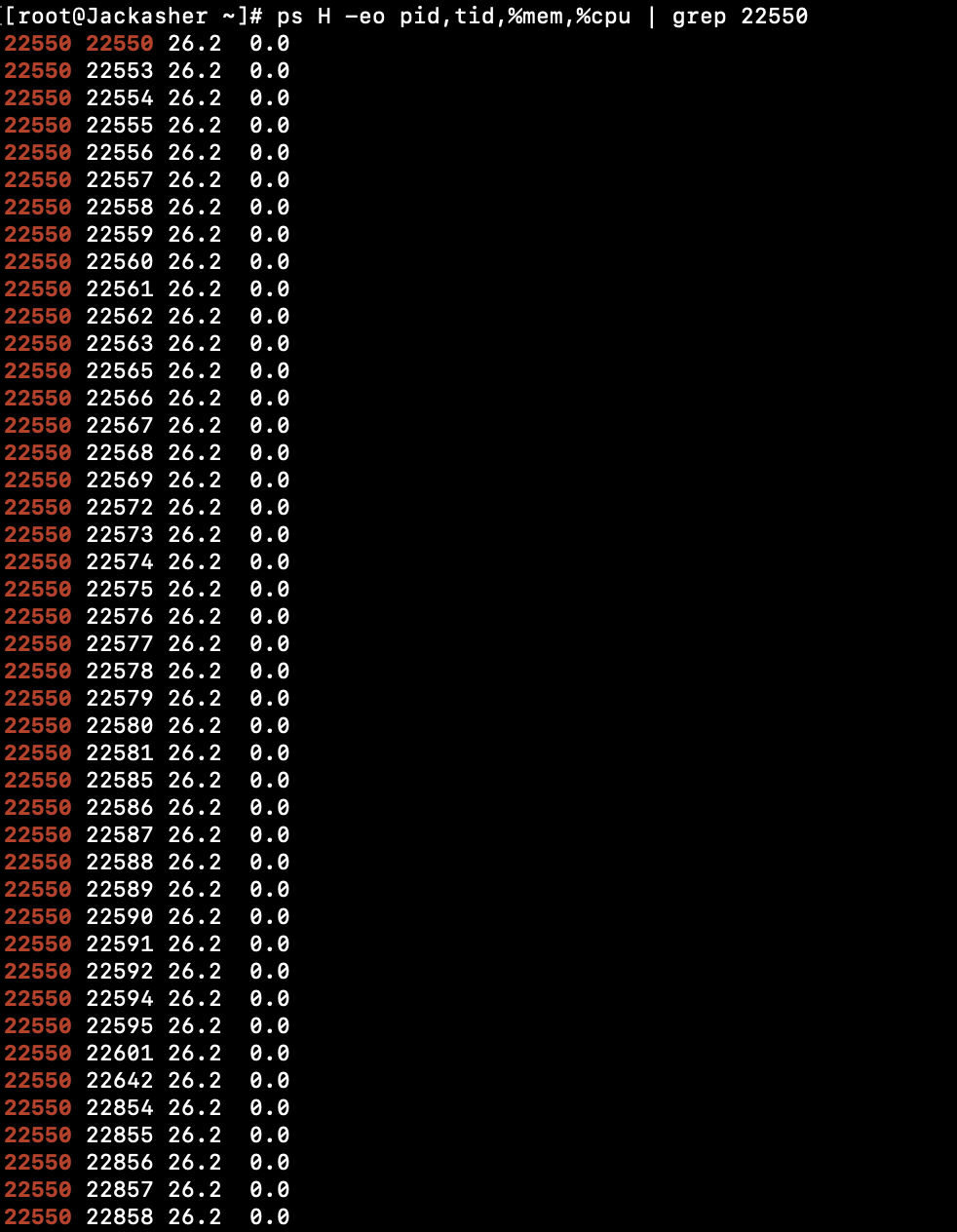
可以使用jstack查看java进程的线程,可以看到有271个线程
1 | |
本地方法栈
Java有一本分代码不是java写的,而是c,这些使用的方法就是本地方法栈, 为naive方法,例如clone, notify, hashCode,
堆(Heap)
堆是对象的空间,是共享的,
例如设置内存、垃圾回收行为等。-X 后面接的选项属于 JVM 特定的功能,但可能并不在不同的 JVM 实现中通用。
例如:
•-Xmx:设置最大堆内存大小。
•-Xms:设置初始堆内存大小。
•-Xss:设置每个线程的栈大小。
2048mb只够27次添加
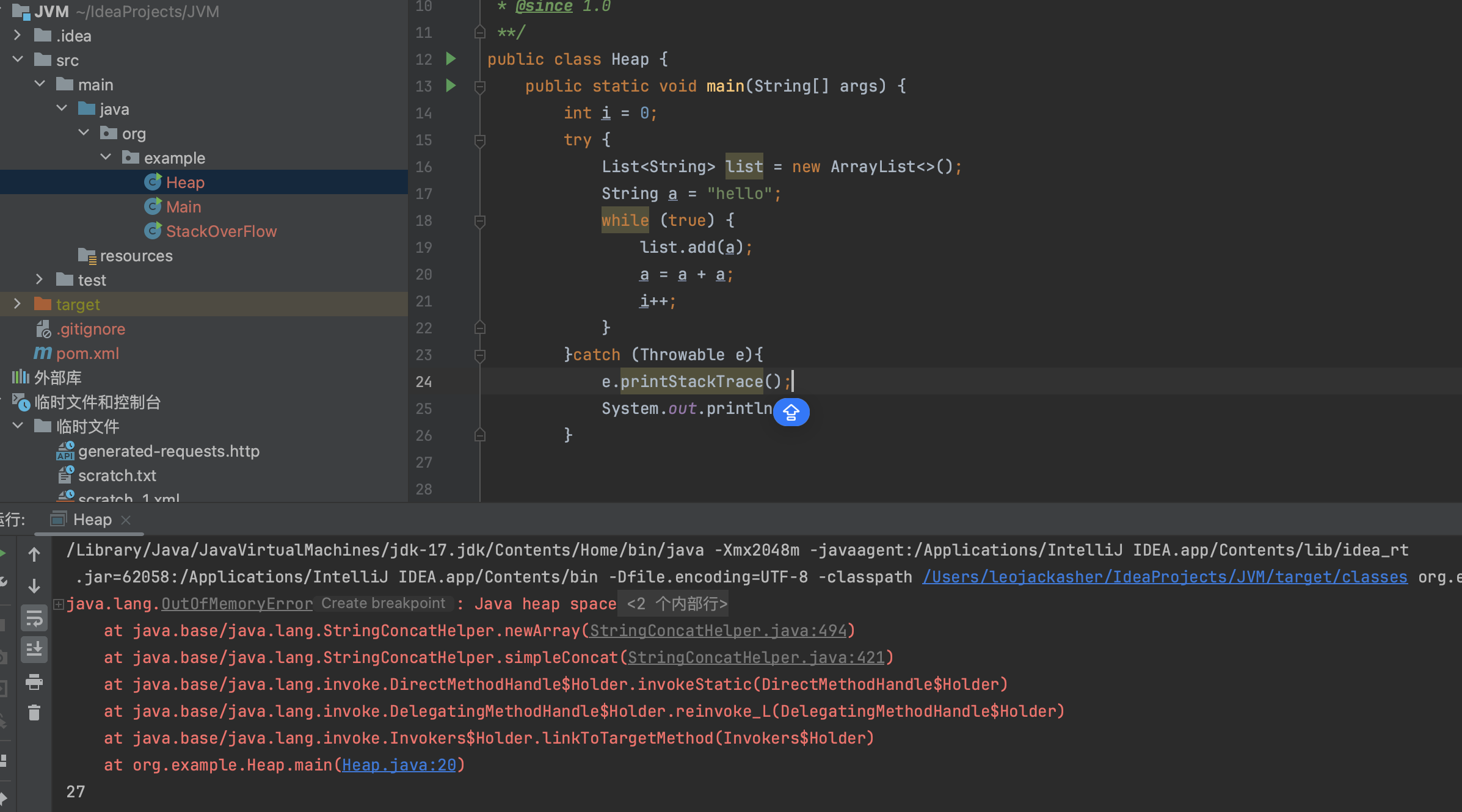
查看堆内存
- jps
- jmap
- jconsole
jconsole也太厉害了
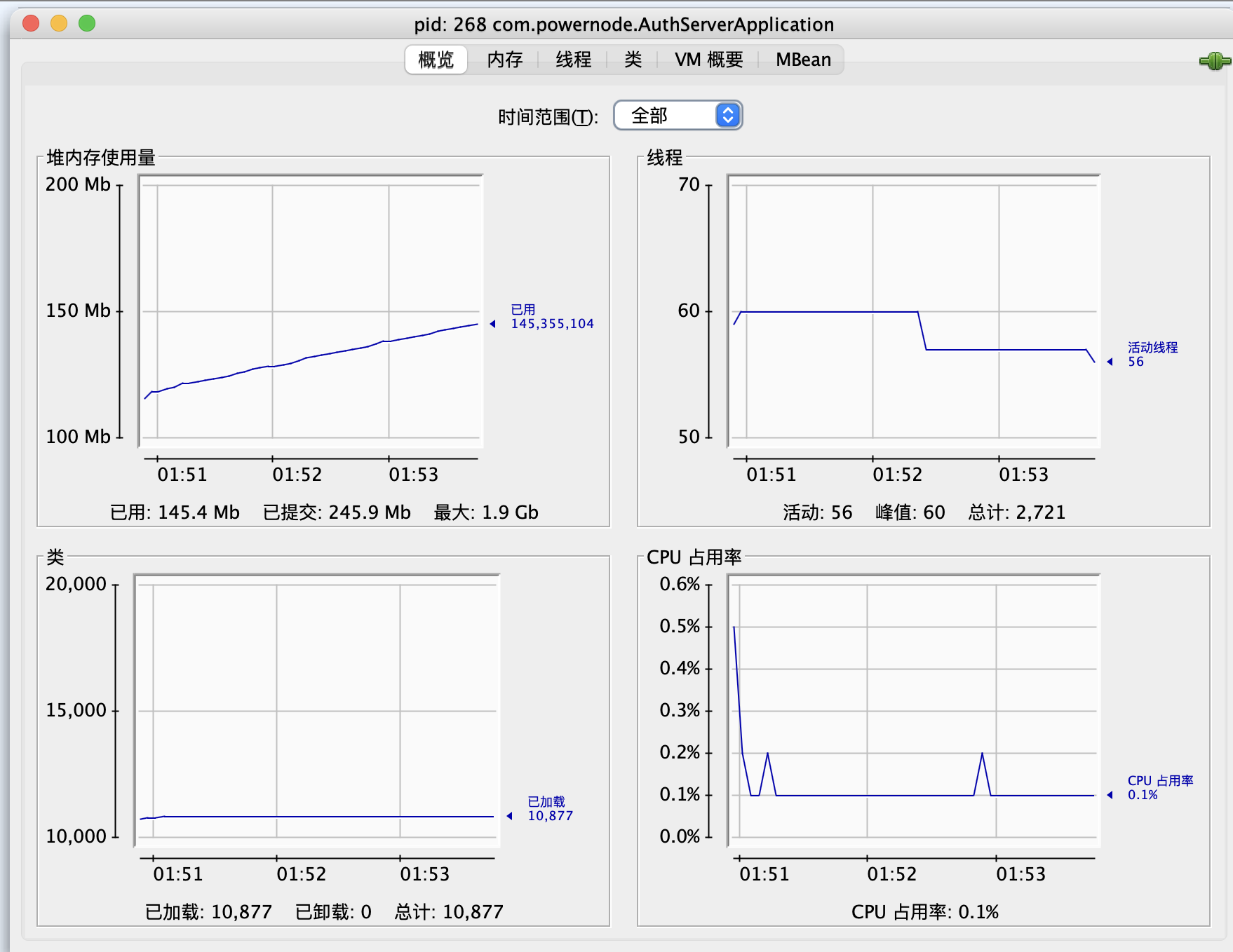
当使用new Byte[1024 * 1024 * 10]时,会创建10MB的堆空间, 除了jconsole以外,还有一个工具,jvisualvm,只不过在JDK8之后被移除了,需要单独下载,这个有个分析堆的功能,可以找到占用堆最大的类

方法区
在JVM1.6时,方法区是在JVM里面, 但是1.8后,就把方法区放在了本地内存, 由元空间实现(Metaspace),使用-XX:MaxMetaspaceSize=8m设置方法区大小
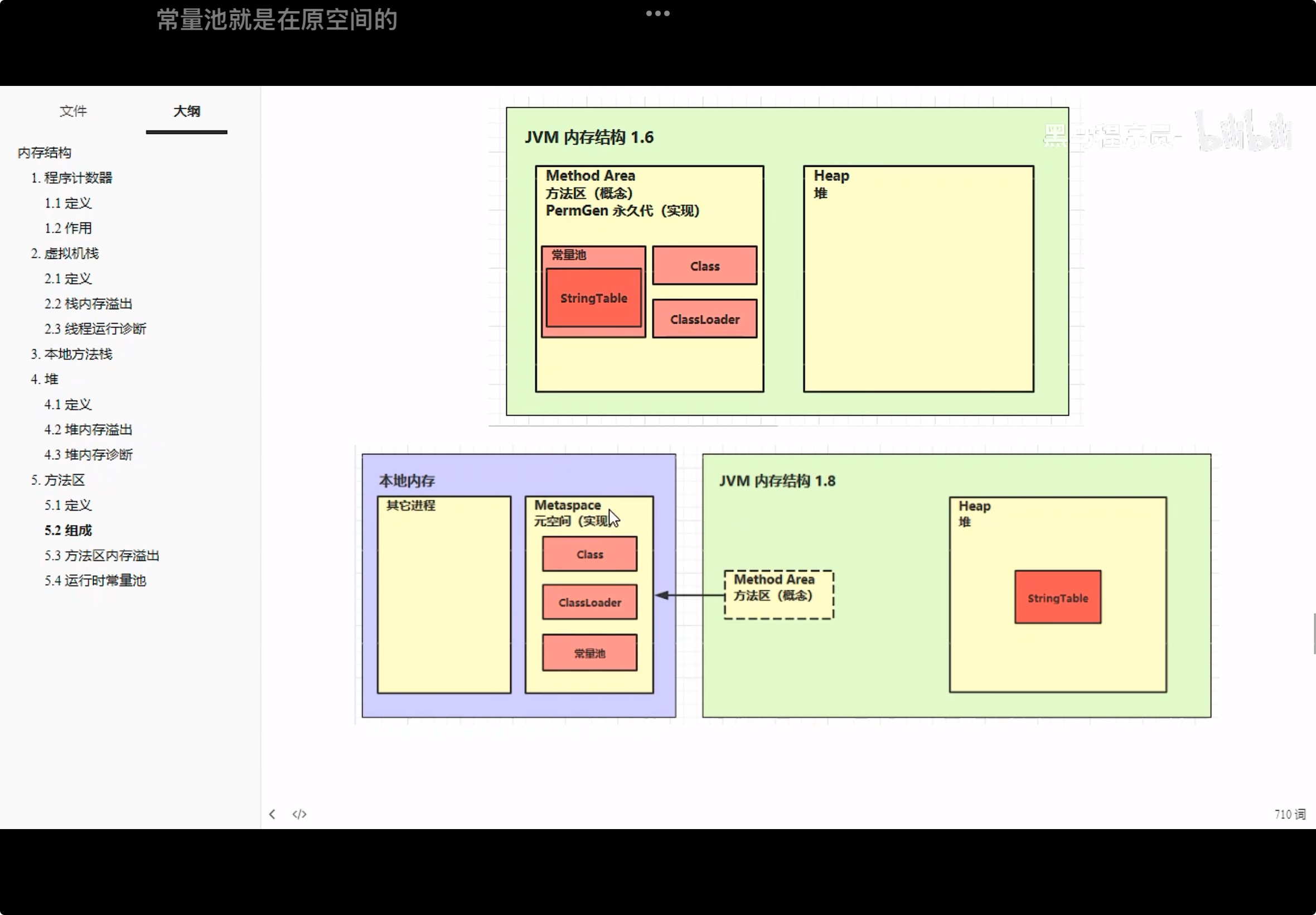
二进制字节码包括了类的基本信息, 常量池,类方法定义,包含虚拟机指令,我们可以通过javap,反编译一个文件看看,可以看到有构造器和主方法
1 | |
使用javap -v完整反编译后得到
1 | |
该部分为类的基本信息
1 | |
然后是常量池
1 | |
最后是方法信息
1 | |
我们可以理解为,方法区和常量池都在.class文件里面, 常量池就是一张表,虚拟机通过指令找到这张表的类名,方法,常量等, 虚拟机运行时,常量池会被加载进运行常量池,虚拟地址,变成真实地址
StringTable
这是JVM用来存放字符串常量的地方,这个时候还没有加载进java的字符串常量,可以通过-XX:StringtableSize来设置大小,该对象底层也是hashTable,当Size设置过小,会导致加大冲突,减少运行效率
. 哈希计算:
• 当插入一个键值对时,Hashtable 使用哈希函数计算键的哈希值,并将其映射到数组中的一个索引。
2. 插入:
• 如果该桶为空,直接将新的 Entry 放入。
• 如果该桶已经有一个或多个 Entry(即发生了哈希冲突),则在链表的末尾插入新的 Entry。
3. 查找:
• 通过哈希函数计算键的哈希值,找到对应的桶。如果桶中有多个 Entry,则遍历链表查找对应的键。
4. 删除:
• 找到对应的桶和链表中的 Entry,将其从链表中移除。
我们可以写一段代码来感受一下, 这个常量池的应用, 传说,推特原本是要存储用户地址,预计是30G, 但是使用了字符串常量池后, 减少到了300MB,真是巨大的进步啊, 我们可以大量读取文本文件来做实验
1 | |
运行该项目,进行阻塞,查看String占的堆内存, 可以看到初始时只有800KB
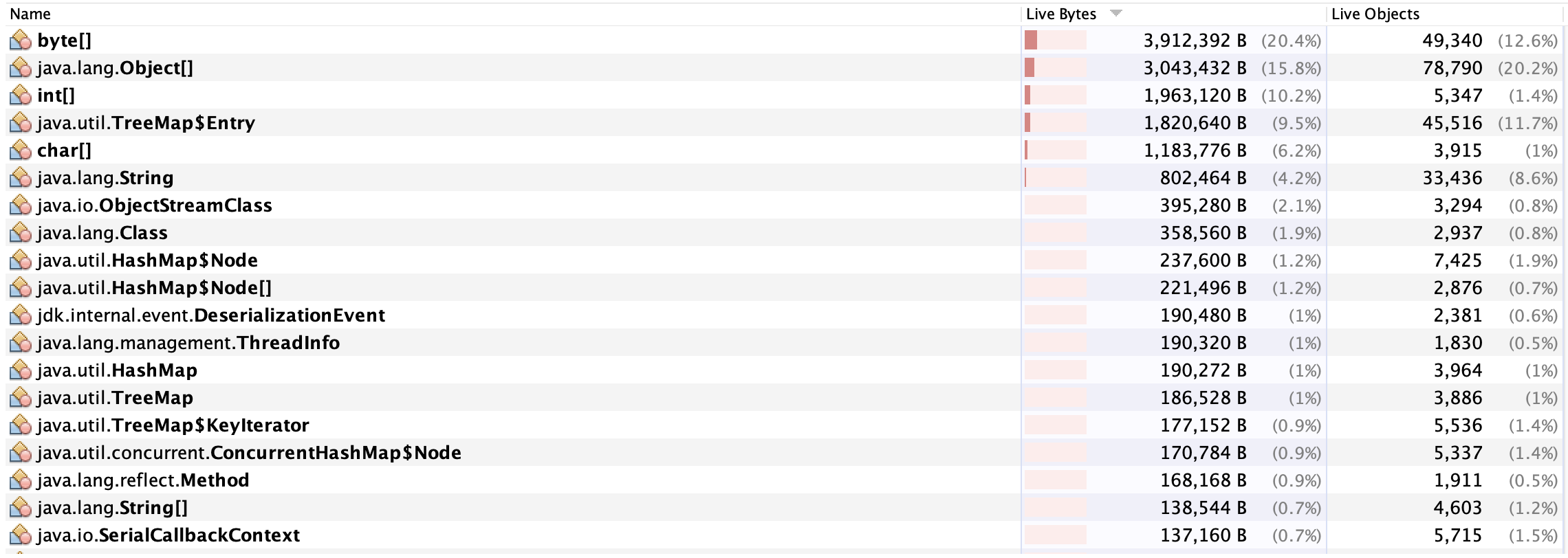
当我们开始运行程序,达到162MB,非常的大了

而我们如果把数据放入常量池
1 | |
那么再来看看String内存占用是多少,一下子缩减到了12MB,这个进步可就大了

直接内存
直接内存就是,直接调用操作系统的内存,最好的例子就是, ByteBuffer, 这个直接内存被操作系统和java可以直接访问,所以读写速度就会更快,原本的读取,是需要从操作系统的缓冲器拷贝到java的缓冲区,这样就会慢很多,不过直接内存是不受JVM回收管理的