Java 基础
Time: 2024-11-02 Saturday 15:34:01
Author: Jackasher
Java 基础
必须要记录一下,不然我发现全部要忘完,我至少要知道我学了什么吧
抽象方法的应用
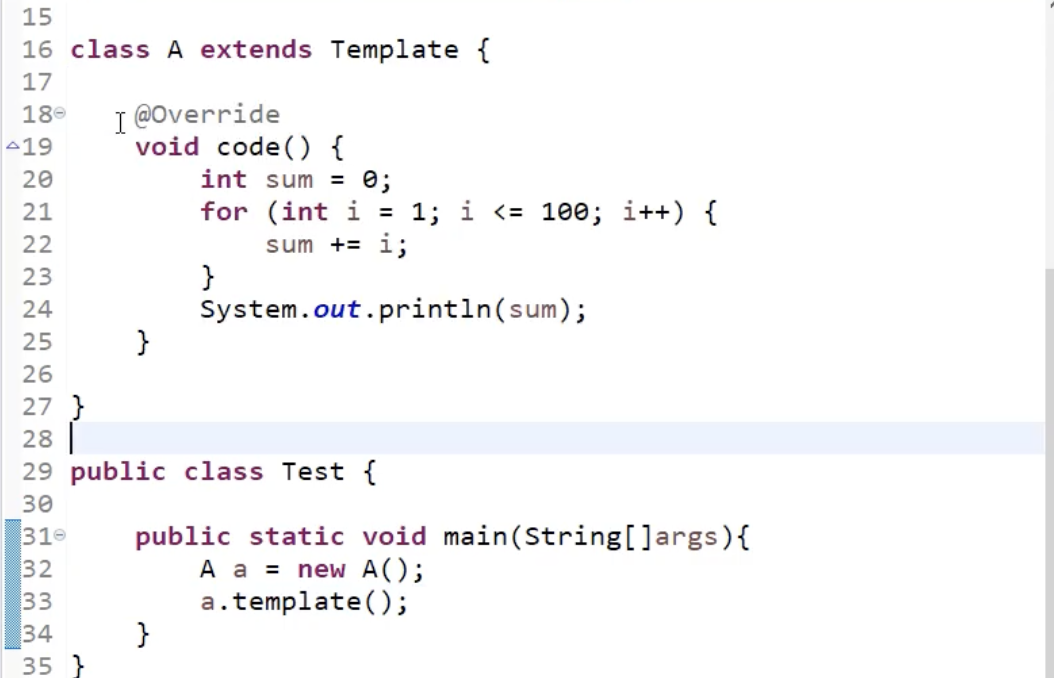
内部类
内部类会被编译成 AB$C
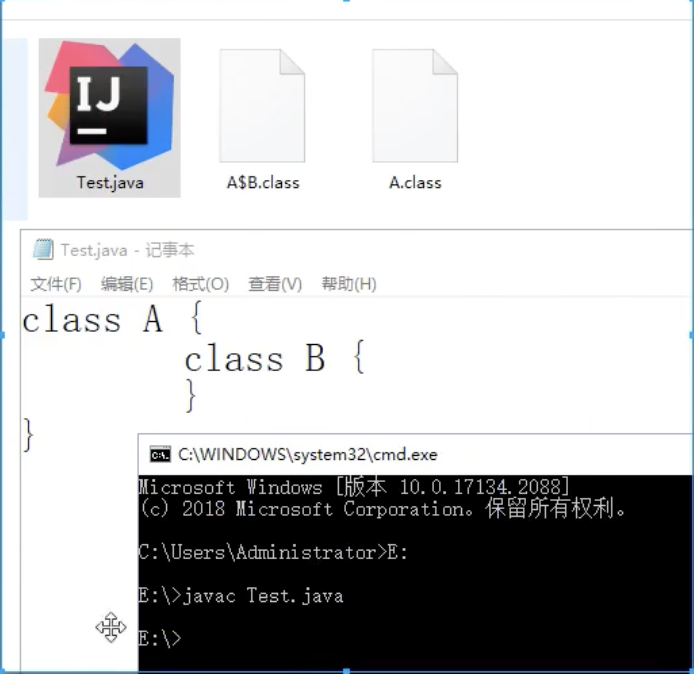
内部类会有外部类的引用, 反编译后B 里面会有 A 的成员变量,但是静态类的内部类是没有的,
什么时候使用内部类
当我们希望一个类可以访问另一个类的所有属性和方法时,就可以使用, 虽然我也想不到这个的使用场景…
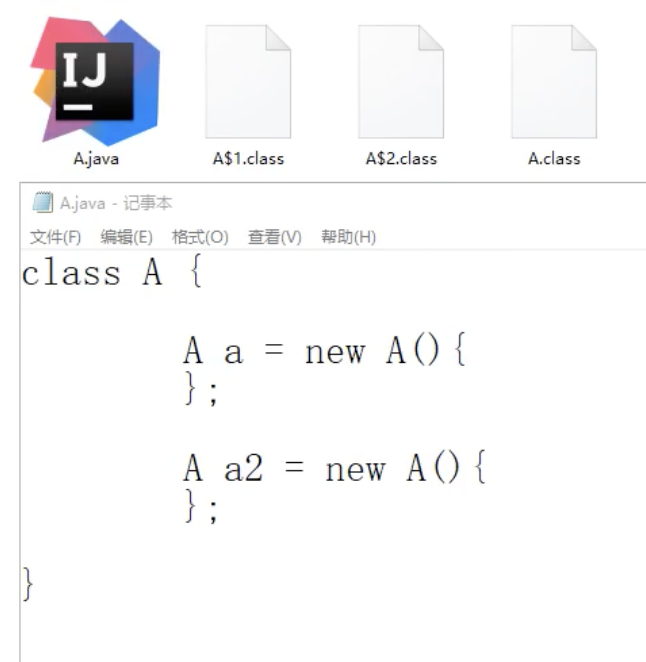
匿名内部类
匿名内部类的字节码文件是 A$1
接口

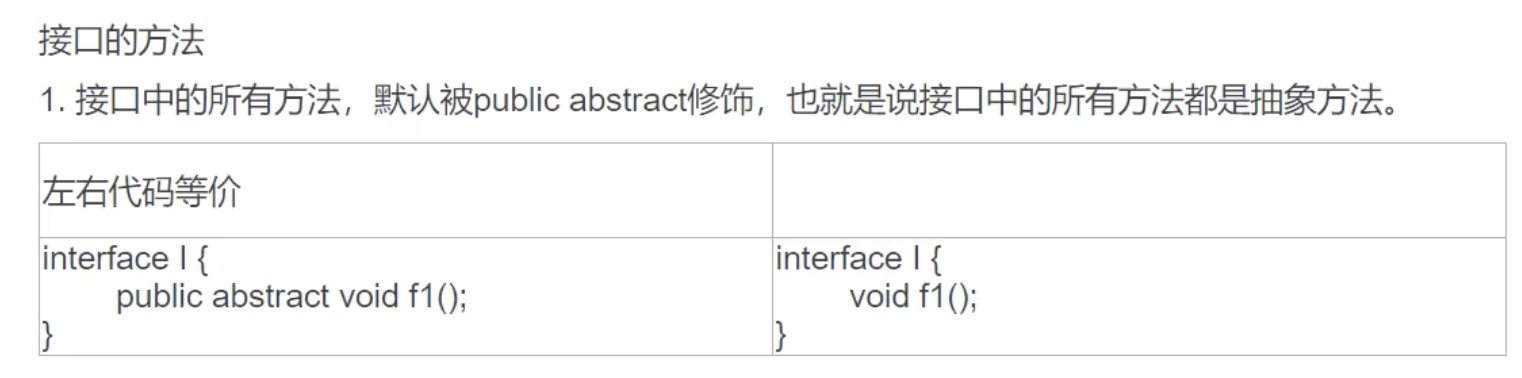
太厉害了这老师,讲接口的变量命名规范时, 指出 JDK 的错误, 于是有了以下的代码
1 | |
流
流的三种分类

其实就是字符和字节的输入输出流,大致就是这四种,所有的都是继承改体系`

Writer 是用 Write把信息输出到缓冲流,
如果是 Reader.read(),那么返回的是读到内容(数字), 如果是 Reader.read(char[] c),则返回的是读到的个数, 内容在 char[]里面, Writer.write(),是把内容写到缓冲区里面, 可以放入 char[]数组, 也可以是数字和字符串

总结来说,直接读写,返回的是读取的内容, 到末尾变 0, 如果有缓存数组, 则会把数据读到数组, 返回读到的个数,字符串可以转换为字节数组,中文操作系统默认是 GBK,java 默认是 unicode,
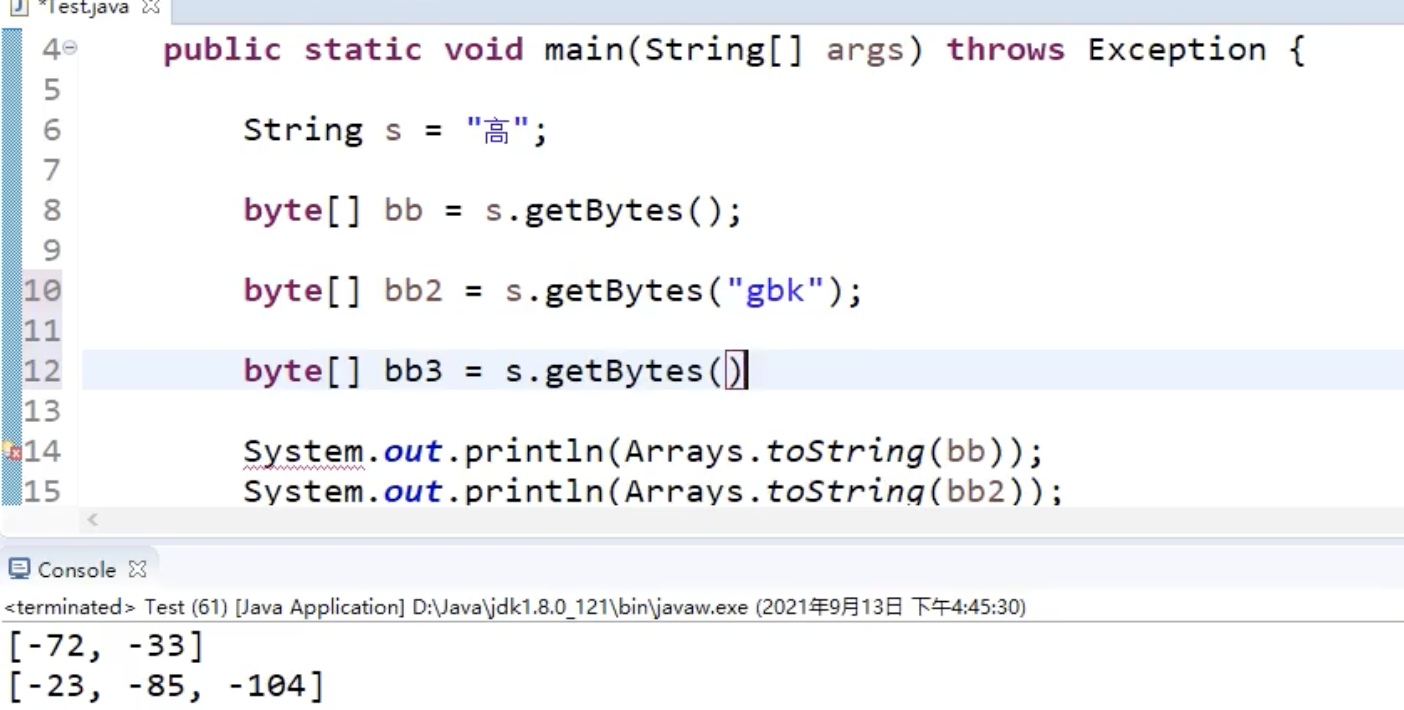
字符流读取时,有的字符是一个字节有的是两个,Reader 怎么知道的
因为编码特点, 如 GBK 的最高位只有汉字是 1, 其他的是 0,所以可以区分,windows10 系统会有一个问题,就是存储猫字符时, 因为开头是 110.就自动就用 utf-8 来存了
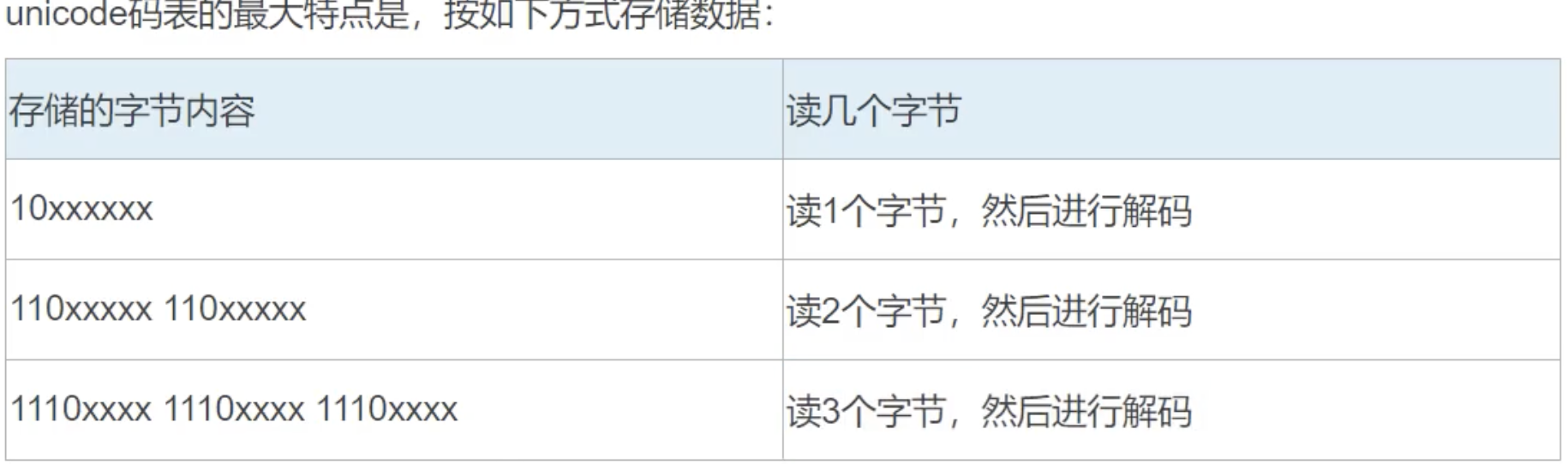
字符流的存储
java 使用 unicode 来存的, 存硬盘前需要先查 unicode 再查 GBK 转化


字节流
咋们发现 Reader.read()是只能传 char 的,而 InputStream 是传 byte 的,
1 | |
Reader.read() 方法返回的是一个 int 类型的数字,表示读取的字符的 Unicode 码点。具体来说,这个返回值有以下含义:
- 字符的 Unicode 码点:
- 如果成功读取到一个字符,
read()方法返回该字符的 Unicode 码点,范围在 0 到 65535 之间。 - 例如,字符 ‘A’ 的 Unicode 码点是 65,字符 ‘汉’ 的 Unicode 码点是 27721。
- 如果成功读取到一个字符,
- 返回值 -1:
- 如果到达文件的末尾(EOF),
read()方法返回 -1,表示没有更多字符可以读取。
- 如果到达文件的末尾(EOF),
- 读入字符和字节的区别:
Reader是字符流,因此它处理的是字符,而不是字节。即使内部实现可能会处理字节,read()方法最终返回的是字符的 Unicode 码点。
InputStream.read() 方法在 Java 中返回的是一个 int 类型的数字,表示读取的字节值。具体来说,它的返回值有以下含义:
- 字节值:
- 当成功读取到一个字节时,
read()方法返回该字节的值,范围在 0 到 255 之间。这个值是字节在 8 位中表示的无符号整数。 - 例如,字节值 65 对应的字符是 ‘A’。
- 当成功读取到一个字节时,
- 返回值 -1:
- 如果到达文件的末尾(EOF),
read()方法返回 -1,表示没有更多字节可以读取。
- 如果到达文件的末尾(EOF),
- 读入字节和字符的区别:
InputStream是字节流,因此它处理的是原始字节,而不是字符。如果要将字节转换为字符,需要使用字符编码进行转换。
为什么不能用字符流读视频图片等文件
因为字符流有一定读取的规则, 而视频图片的二进制有许多无法被解码的数据, 找不到码表就会被解析为?或者方框,当再进行操作时, 这些?就会被解析为 unicode 的数字码点 63, 其实如果字符流就是会对编码的规则进行读取,列如utf-8的汉字就会直接读取三个字节, 然后将其装换为 unicode 的码点, 而音频文件,有可能恰好有符合这些规则的数据,被转为码点,导致数据被改变
重点就在这个解码的过程,如果字符编码和解码正常是可以用字符流的, 重点是编码时会丢失数据
写入时默认会覆盖原文件,可以采用这种方式
1 | |
为什么快速的 io 操作会非常消耗性能且慢,机械硬盘的指针会在两个方向来回快速动

DateStream(字节过滤流)
就是一次性可以读很多个字节
InputStream.read() 方法返回的是 int 而不是 byte。这样做的原因:
用 -1 表示文件末尾:
InputStream.read()的返回值范围是-1到255,其中-1专门用来表示“没有更多字节可以读取”。- 如果返回类型是
byte(范围-128到127),-1就会和读取到的数据冲突,因为实际数据也可能包含-1。
InputSreameReader
这是把字节流转换为字符流,传入字节流和码表就可以
补码
计算机里面只存补码,正数开头是 0,负数开头是 1,负数补码第一位还是 1,计算出来的数据 也是补码
异常
异常分为检查型异常和运行时异常 ,运行时异常会自动转移
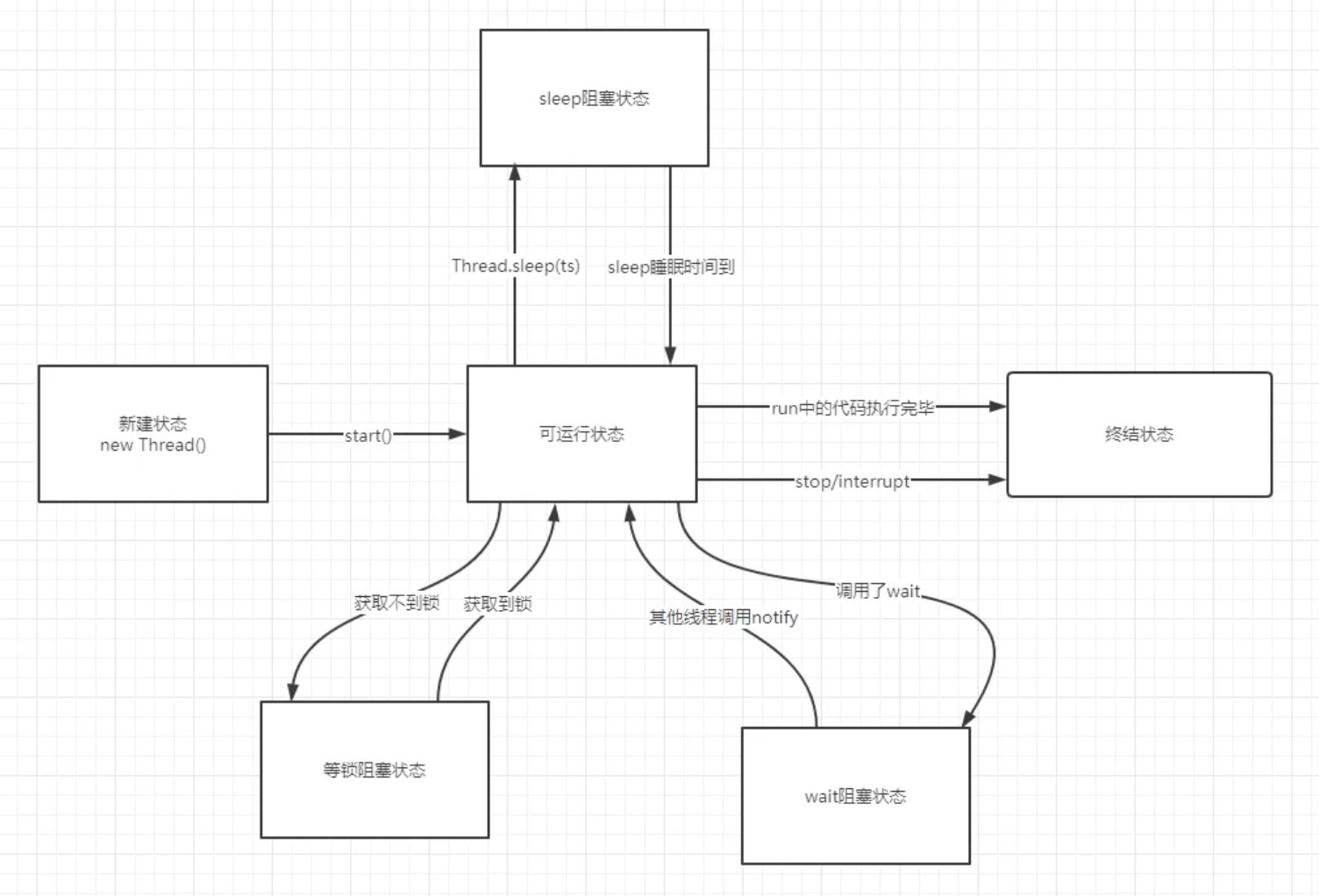
线程
线程有两种启动方式,一种是继承 Thread 后, A.start(),一种是实现 runnable 接口,然后 Thread.start( a ),
线程状态
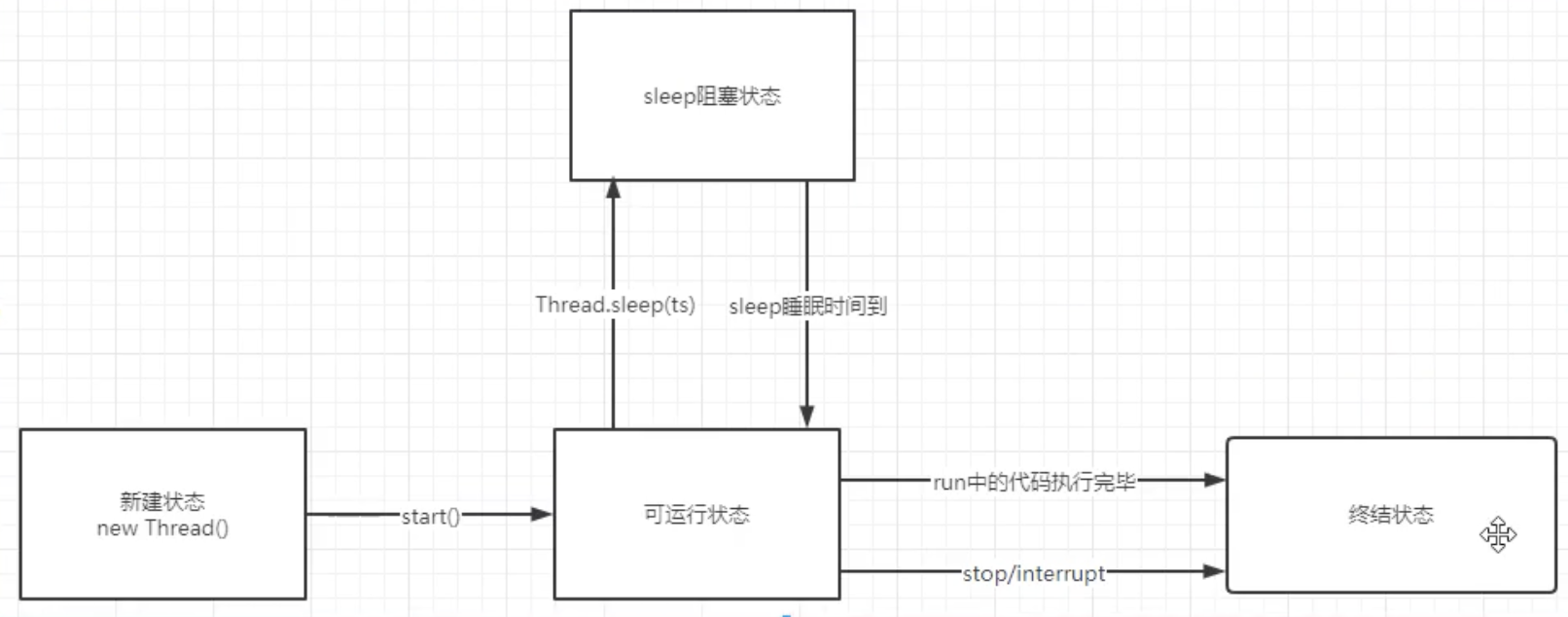
1.新建状态
就是刚创建还没有运行时的状态
2.可运行状态
就是加入线程了, 可以去抢 cpu 了
线程如何停止
采用 interrupted 来为线程设置信号量
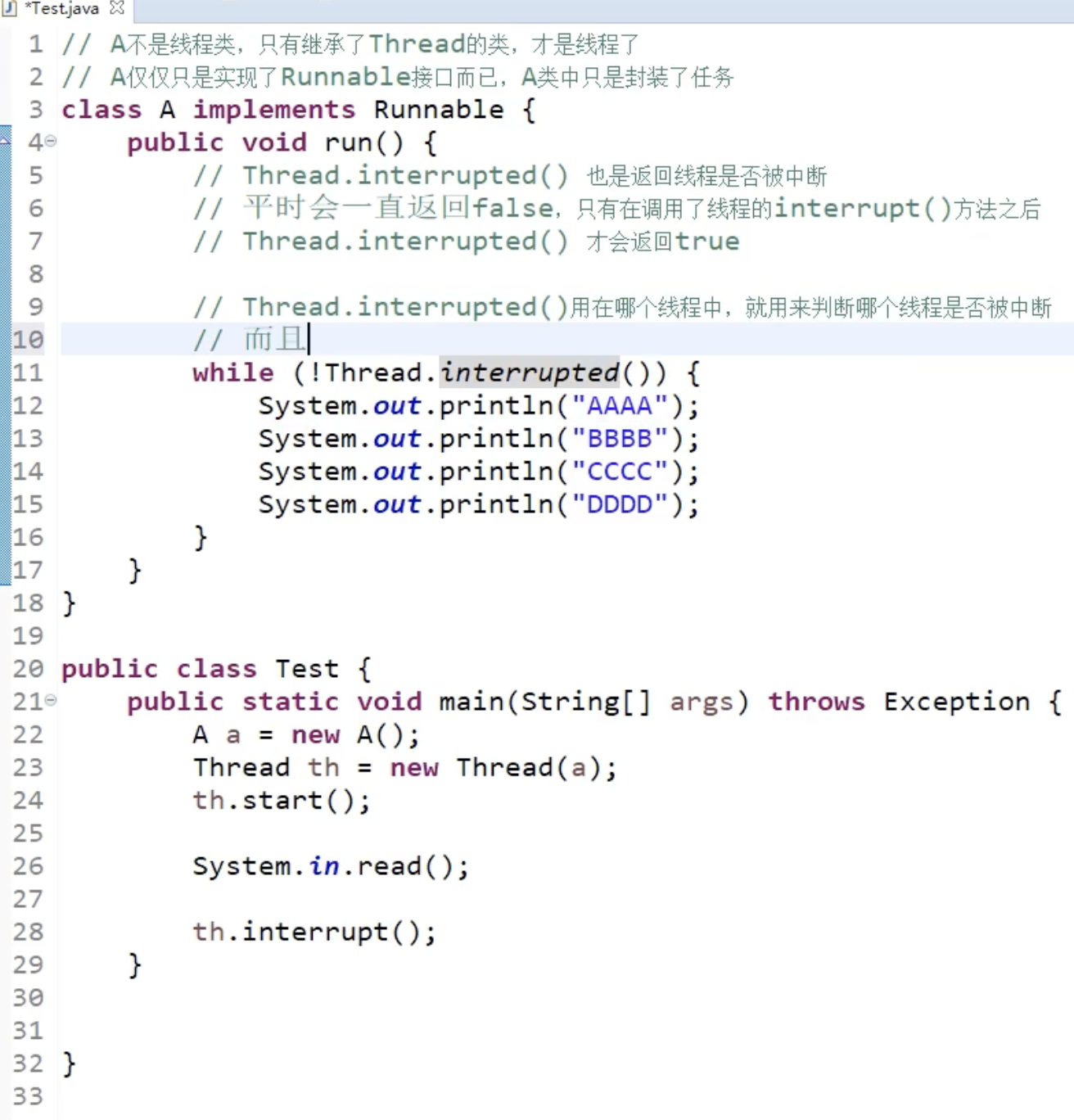
为什么要用枚举
为了可读性, Thread.MAX_PROITY 比单单一个数字 1 的可读性好太多了
模版方法和策略模式
突然发现这个线程的开启不就是这两个方法吗, 实现 Runnable 放入 Thread 就是策略模式, 继承 Thread 然后直接调用 start 方法不就是标准的模版方法吗?
代码一定是按照顺序执行的吗?
不是, 会打乱, 但是会保证结果一样
对象锁到底是什么
其实就是一个标记,在字节码层面,有个地方标记,01 就是没锁,10 就是重量锁之类的,
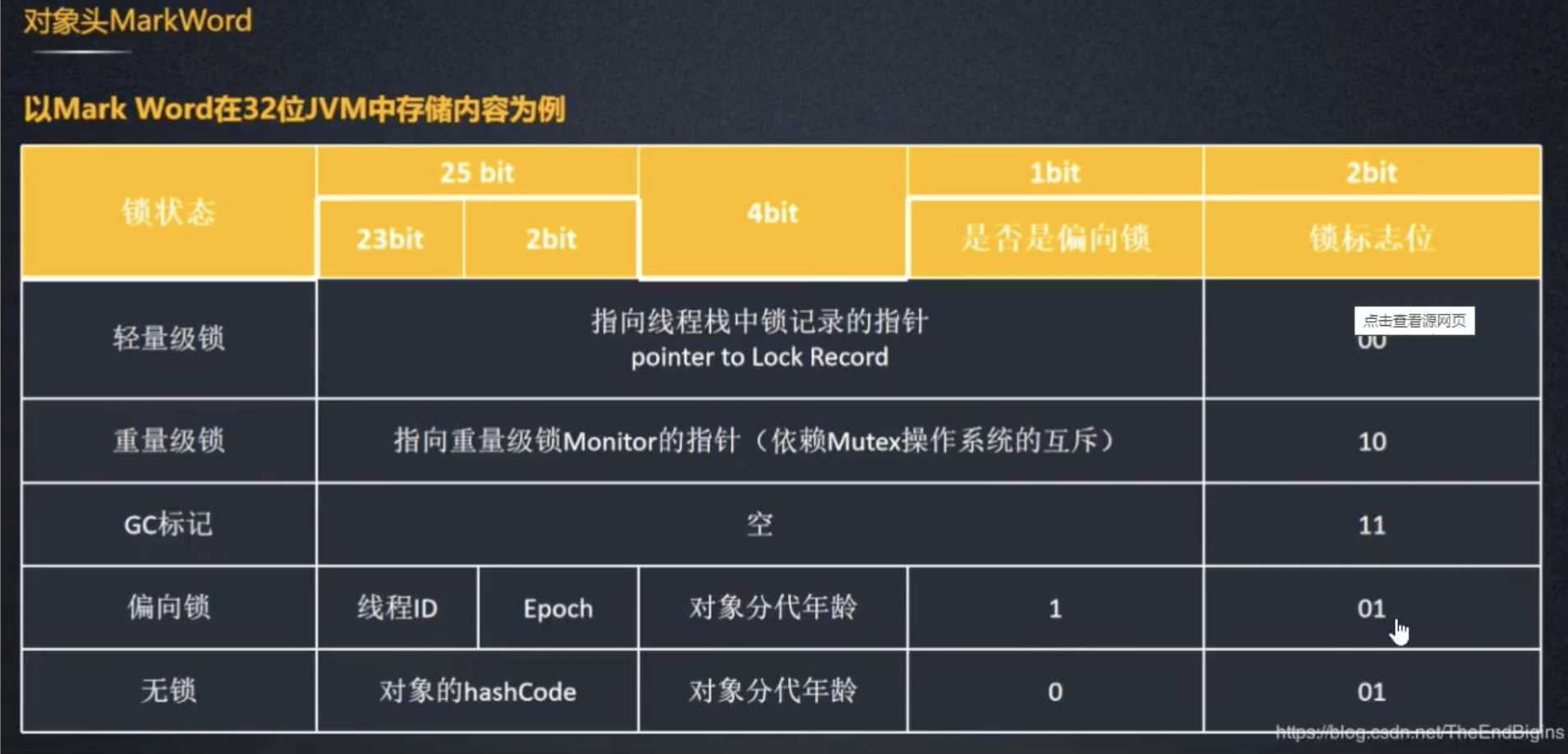
对象头是 JVM 中每个对象都包含的基本部分,包含了管理对象的元数据:
- Mark Word:用于存储锁状态、对象的哈希码、GC 标记等信息。根据锁的状态(如无锁、偏向锁、轻量级锁、重量级锁),
Mark Word会动态改变其内容。 - Class Pointer(类指针):指向该对象所属的类的元数据,帮助 JVM 知道该对象的类型,并访问该类型的字段和方法信息。
- 数组长度(仅适用于数组对象):对于数组对象,头部会额外包含数组的长度信息。
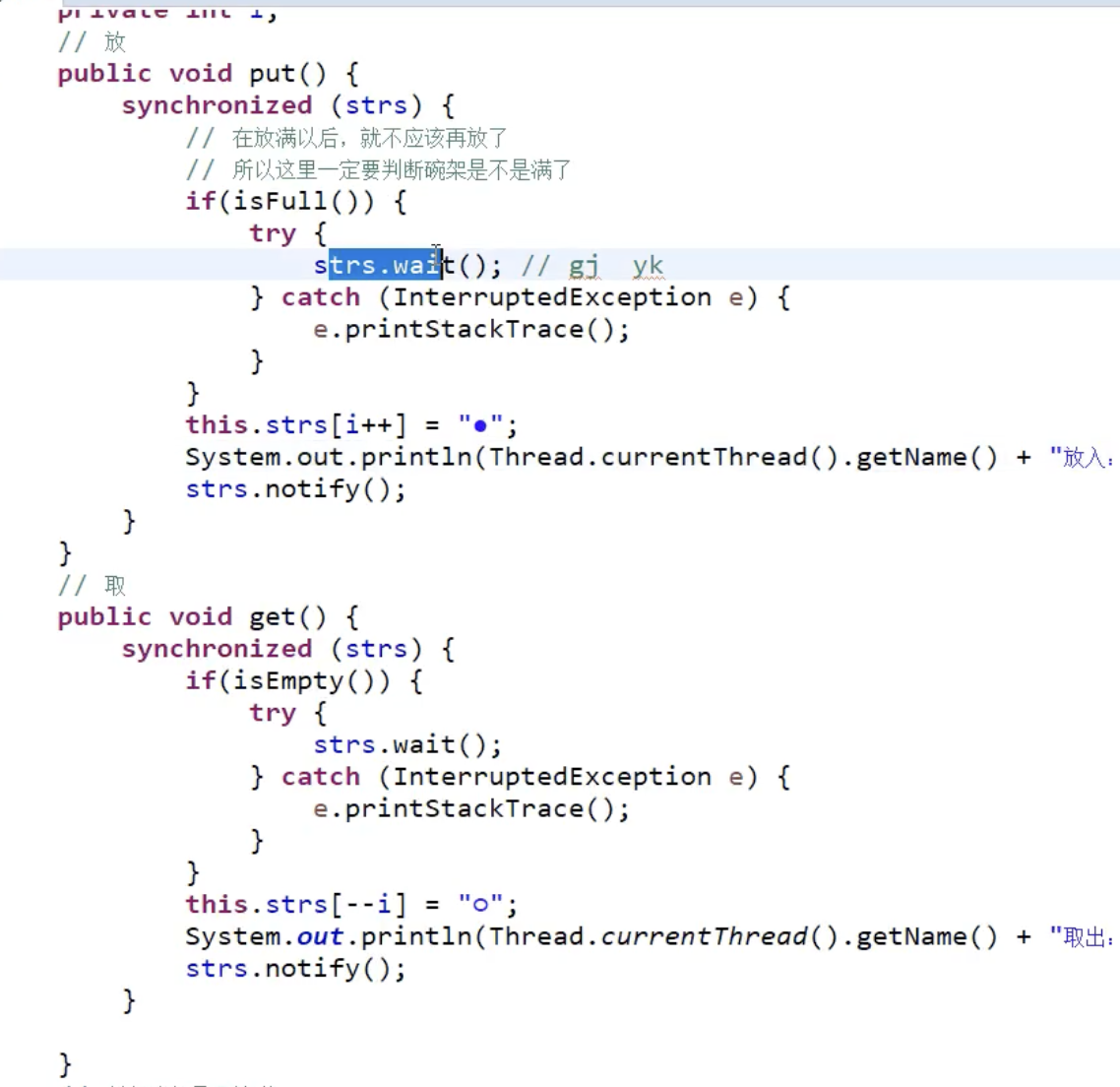
这样的代码也是线程不安全的,问题的根本在于 wait()会释放当前的锁, ,所以这个synchronized 就失效了,没有原子性了,wait 方法 必须在持有对象锁的情况下调用,否则会抛出 IllegalMonitorStateException 异常。这是因为 wait方法的设计要求线程首先获得对象的锁,以便能够协调线程的等待和唤醒操作,为什么要拿到锁,为了释放锁,不然你在那一 wait 就卡死了,
解决方式是判断改成 while
方法锁
在方法前面加 synchronized 就是相当于 synchronized(this){},把整个方法体包起来了
静态锁
静态锁理论上无法直接加 synchronized,通常我们调用方法时,其实实例对象会被传进去,才会有 this,因此可以对象上锁,可是静态调用没有这个对象
在 Java 中,对象调用方法 a.f() 的底层实现确实会将 a 传入 f() 方法。这个过程称为“隐式传递”,且 a 对象在方法内部通过 this 关键字来引用。
具体细节
当调用 a.f() 时:
- 隐式传参:编译器在编译时会把
a作为第一个参数传递给f()方法。方法f()的参数列表和内容不变,但a在方法中作为this对象出现。 - 字节码实现:在字节码中,Java 使用
invokevirtual、invokespecial等指令来调用方法。编译时会生成代码,将调用对象(a)作为第一个参数压入栈顶。 - 方法签名转换:例如,假设方法
f()是void f(int x)。编译后的字节码可以理解为f(a, x),其中a是传入的隐式参数(即this),在方法中表示当前对象实例。
静态锁,锁的是字节码,字节码也是对象
守护线程
在创建线程的时候指定
StringBuilder 和 StringBuffer
这两个都会直接操作字符串的空间
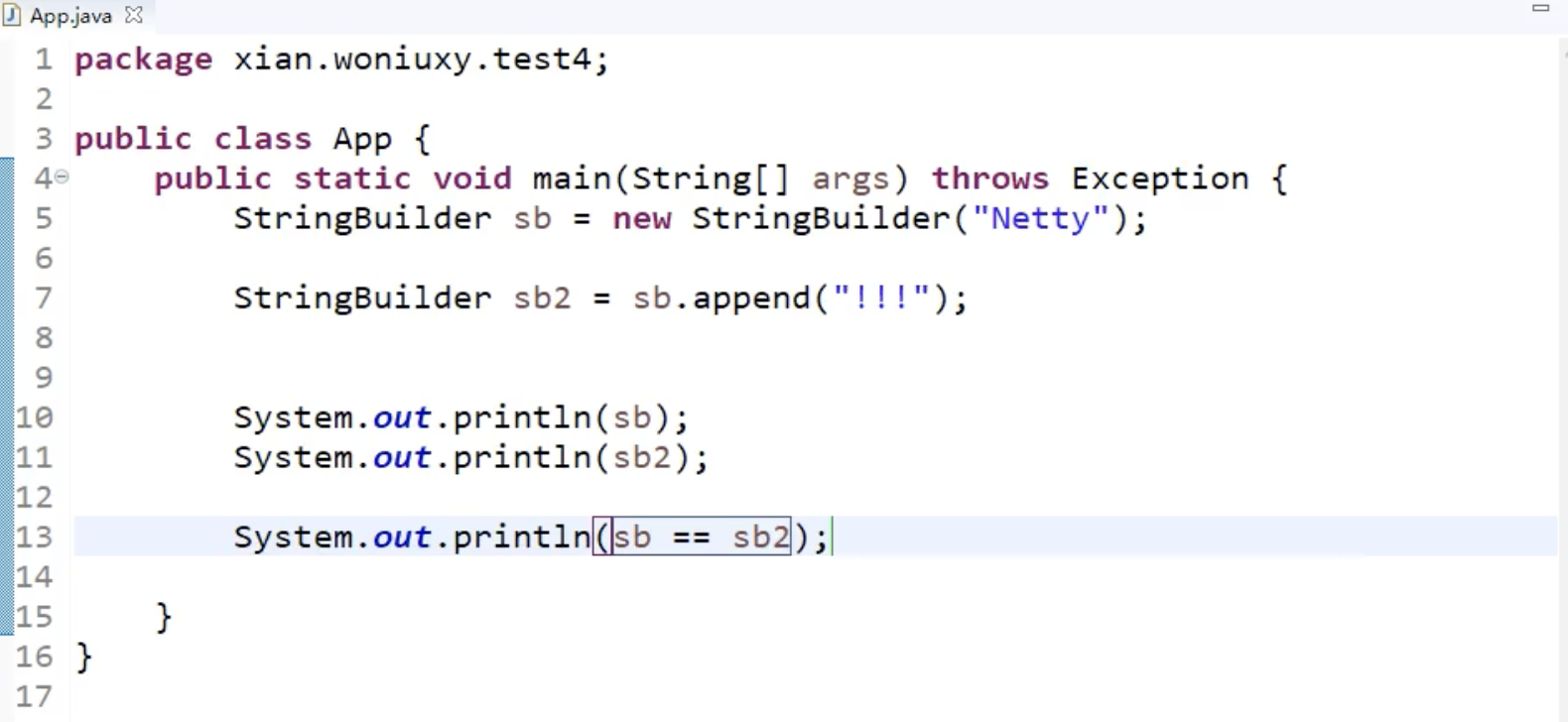
区别是一个线程安全,一个不安全,StringBuilder 是线程不安全的

线程池

集合
集合的家族
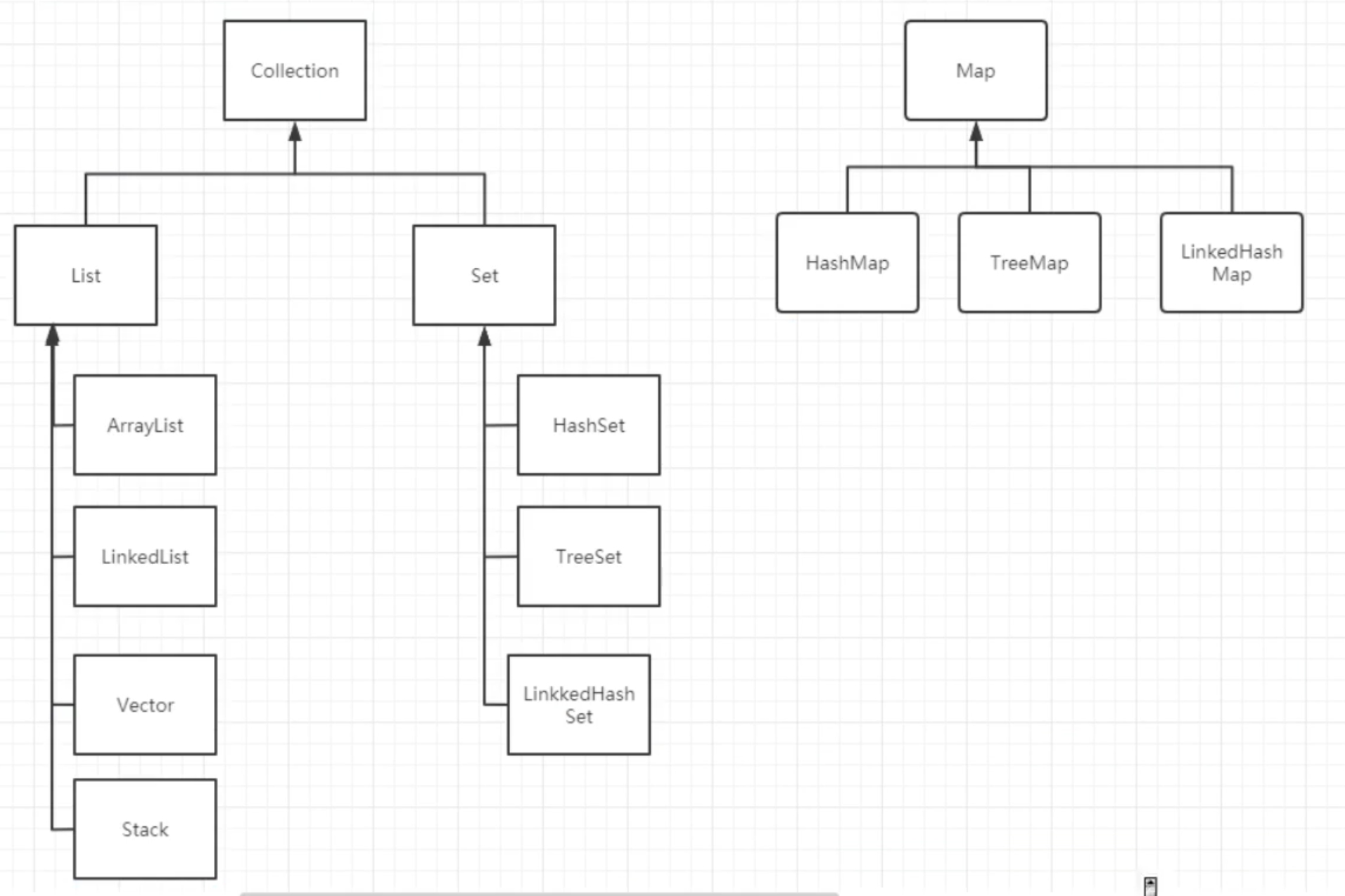
Collection 接口的常用方法
1. add(E e):向集合中添加元素。
2. addAll(Collection<? extends E> c):将指定集合中的所有元素添加到当前集合。
3. clear():清空集合中的所有元素。
4. contains(Object o):判断集合中是否包含指定的元素。
5. containsAll(Collection<?> c):判断集合中是否包含指定集合中的所有元素。
6. isEmpty():判断集合是否为空。
7. iterator():返回一个用于遍历集合的迭代器。
8. remove(Object o):从集合中删除指定的元素。
9. removeAll(Collection<?> c):从集合中删除指定集合包含的所有元素。
10. retainAll(Collection<?> c):保留集合中与指定集合的交集的元素。
11. size():返回集合中元素的个数。
12. toArray():将集合转换为一个数组。
13. toArray(T[] a):将集合中的元素存储到指定类型的数组中。
ArrayList 的方法
ArrayList 实现了 List 接口,继承了 Collection 中的所有方法,并且还提供了以下特定方法:
1. get(int index):返回指定索引处的元素。
2. set(int index, E element):用指定元素替换指定索引处的元素。
3. add(int index, E element):在指定位置插入指定元素。
4. remove(int index):移除指定索引处的元素。
5. indexOf(Object o):返回指定元素首次出现的索引。
6. lastIndexOf(Object o):返回指定元素最后出现的索引。
7. subList(int fromIndex, int toIndex):返回列表中指定范围的视图。
subList 会更改原来的集合
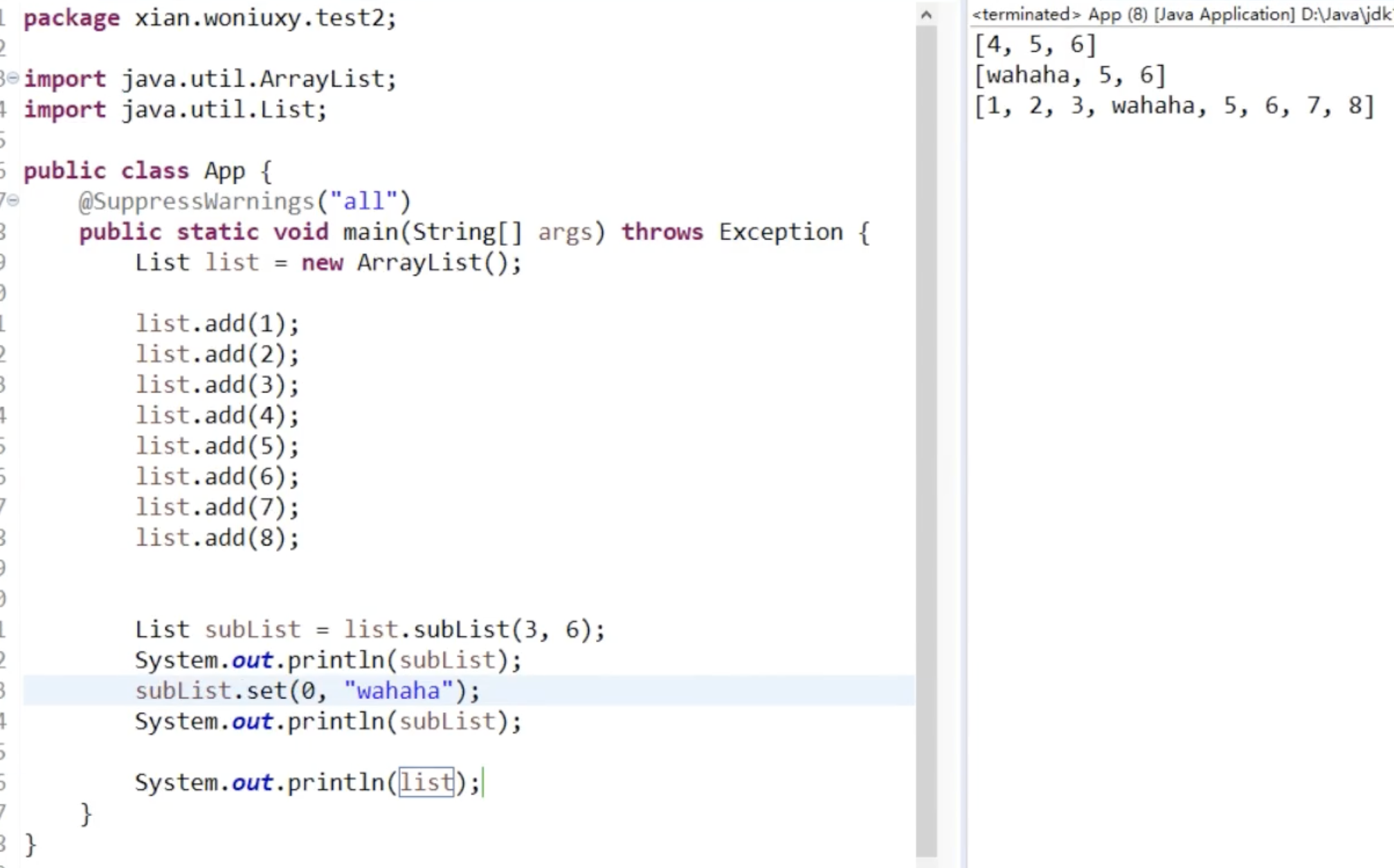
迭代器的 next()其实就是取下一个元素
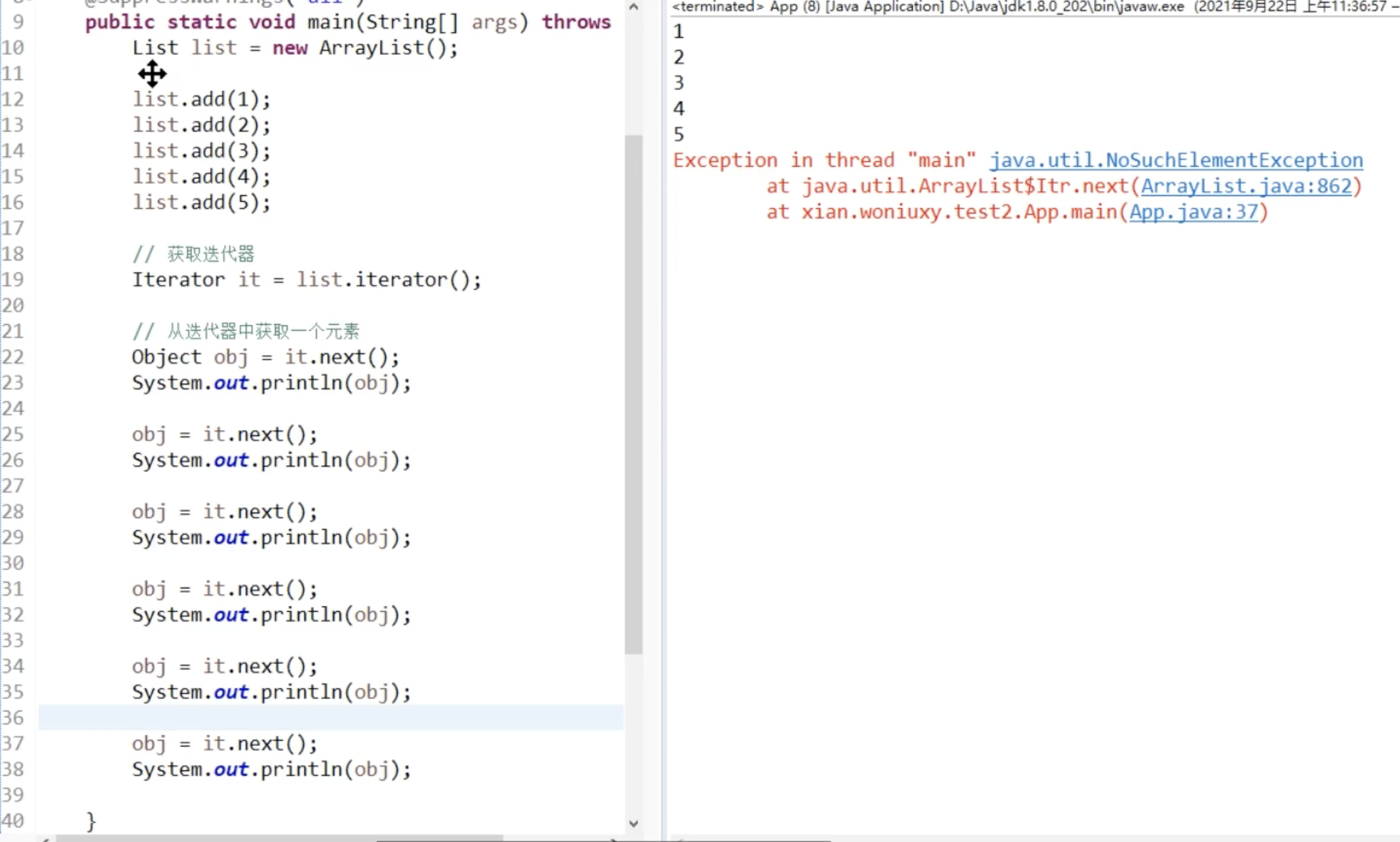
为什么要用迭代器, 明明有了循环通过下标获取
因为只有 ArrayList 是数组, 可以通过下标,其他的只能通过迭代器
ArrayList 查询原理
ArrayList不是线程安全的

为什么一下常见,LinkList 的增加效率居然更低?
因为要先找,找到 i/2 的内存地址,这个过程很慢, 但是加的过程其实是很快的,list.add()会从 0 到下表点,而 LIstiterator 就可以解决,
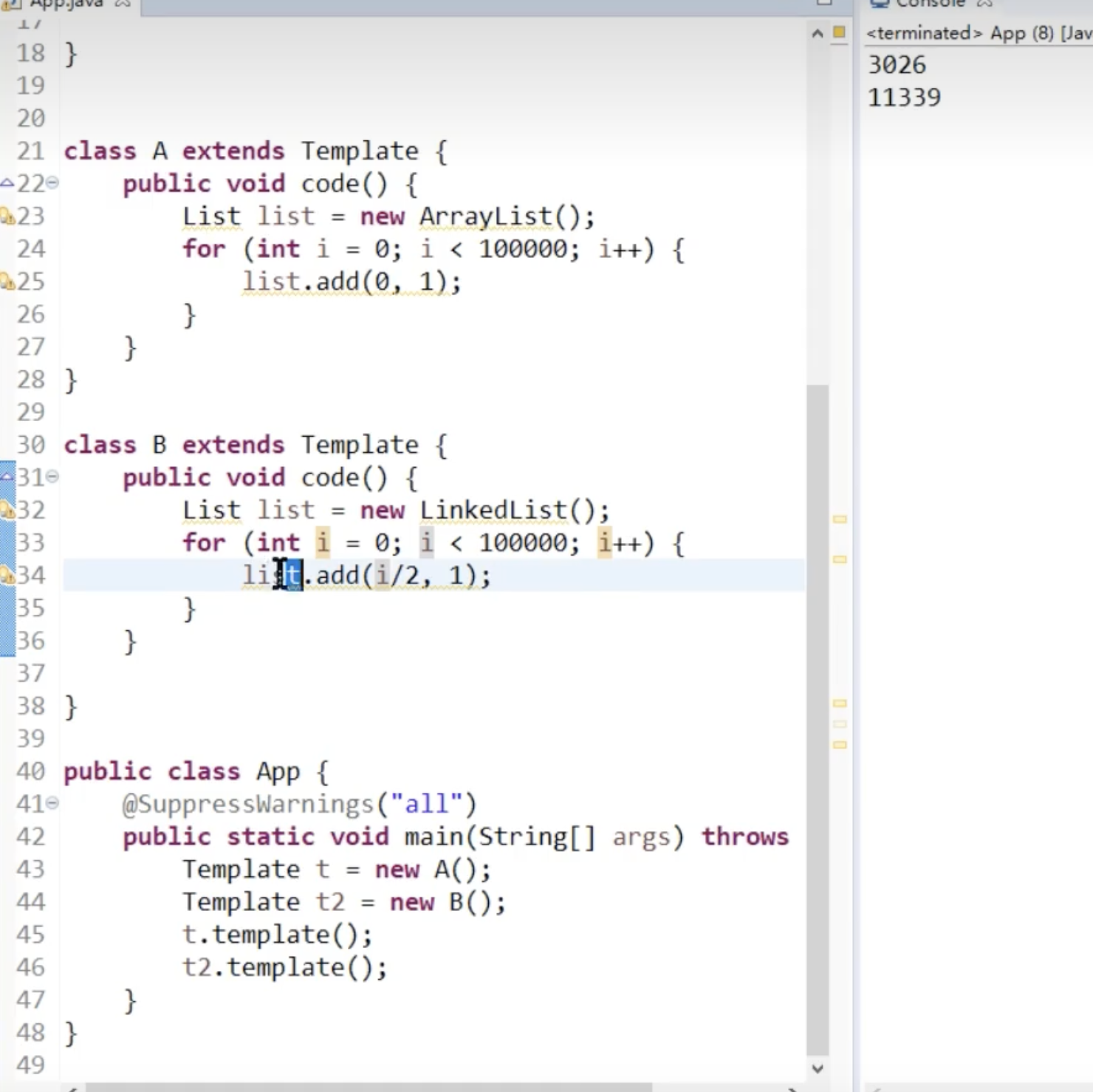
自己设计一个栈
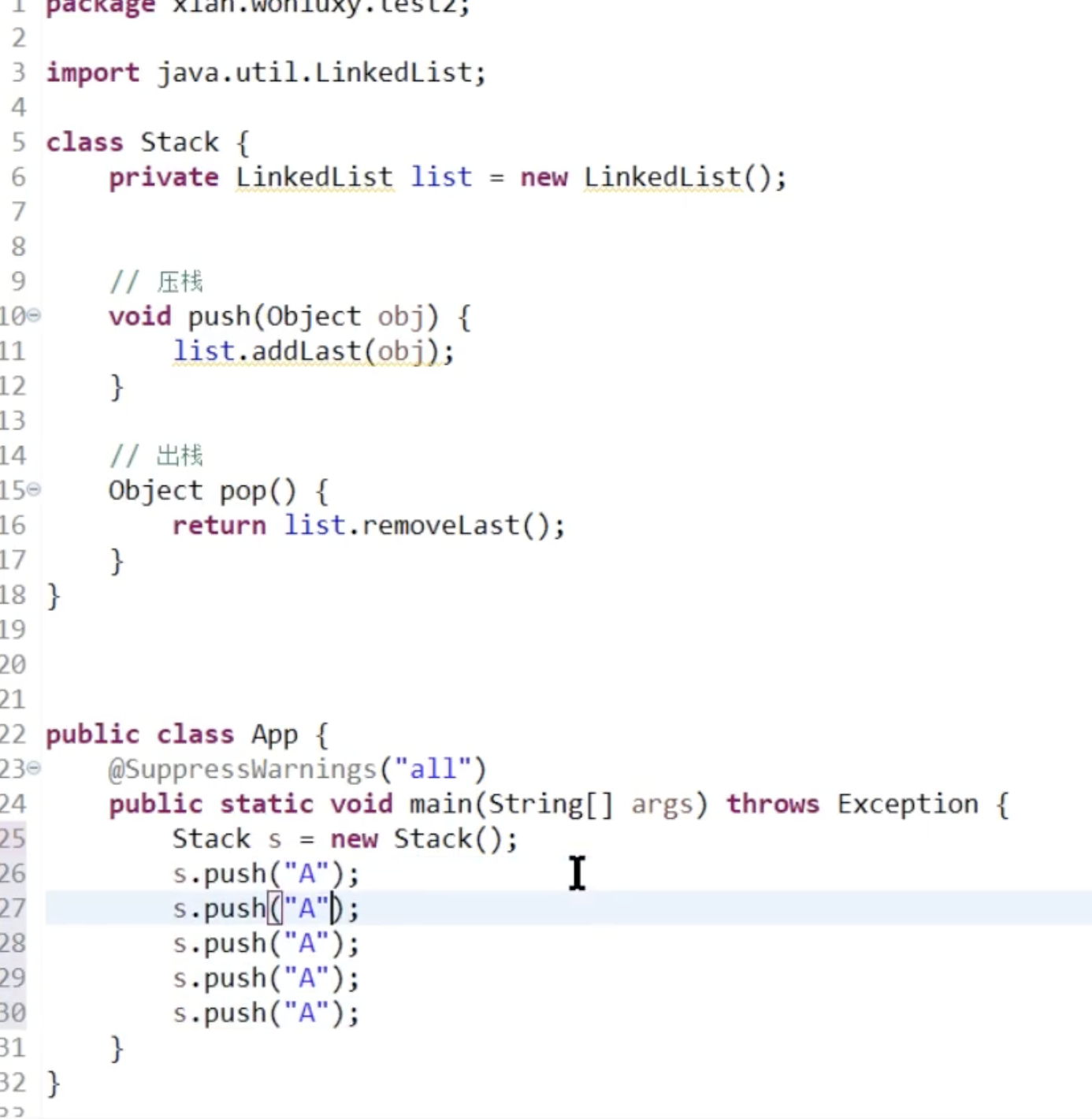
Set
HashSet无论有多少数据,花费寻找时间都是一样的

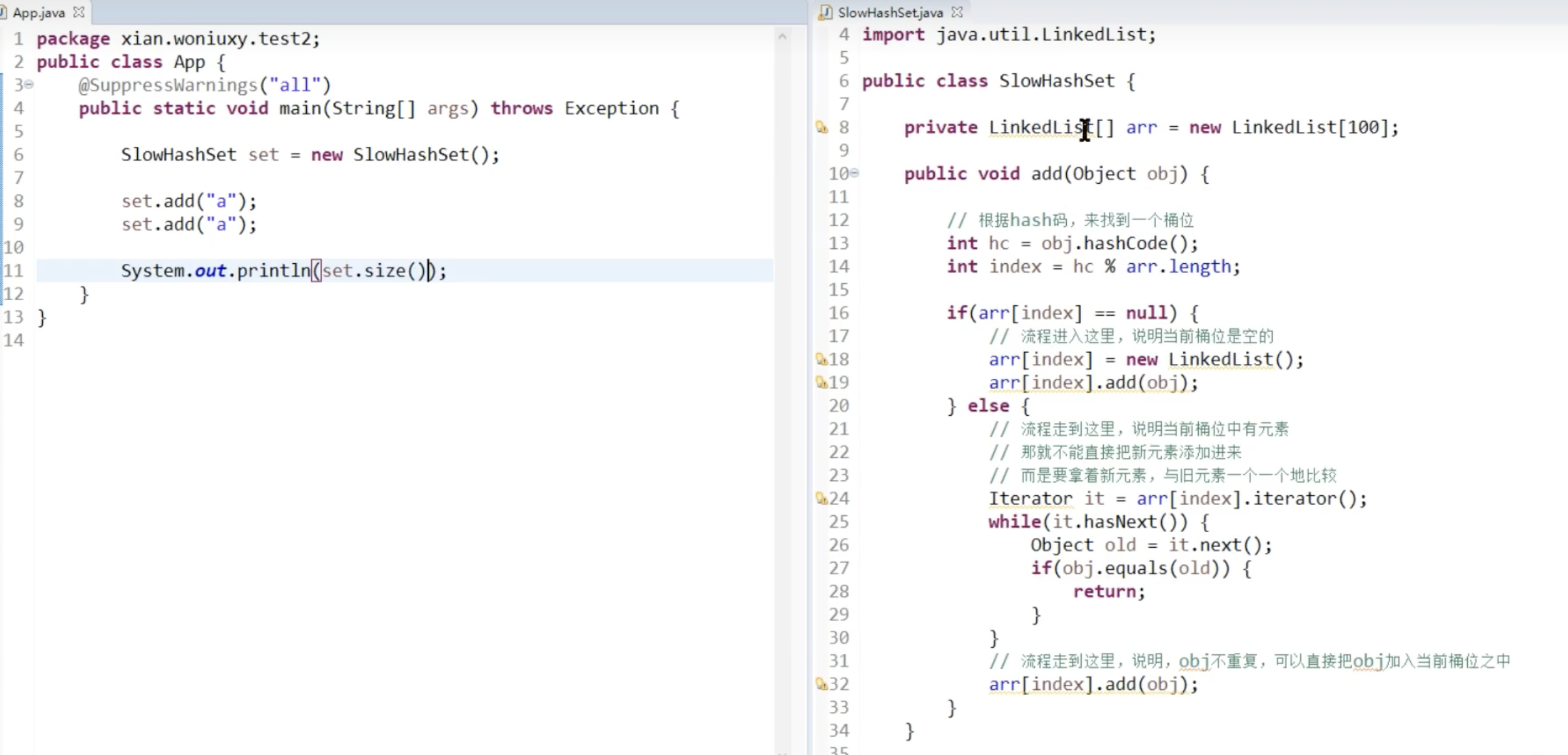
HashMap就是一个LinkedList的数组,存数据时,先计算HashCode,然后看有没有桶位,没有的话就进行对比, 桶位里面有没有重复的值
TreeSet
TreeSet可以直接排序,字符串是比第一个字母
HashSet的实现
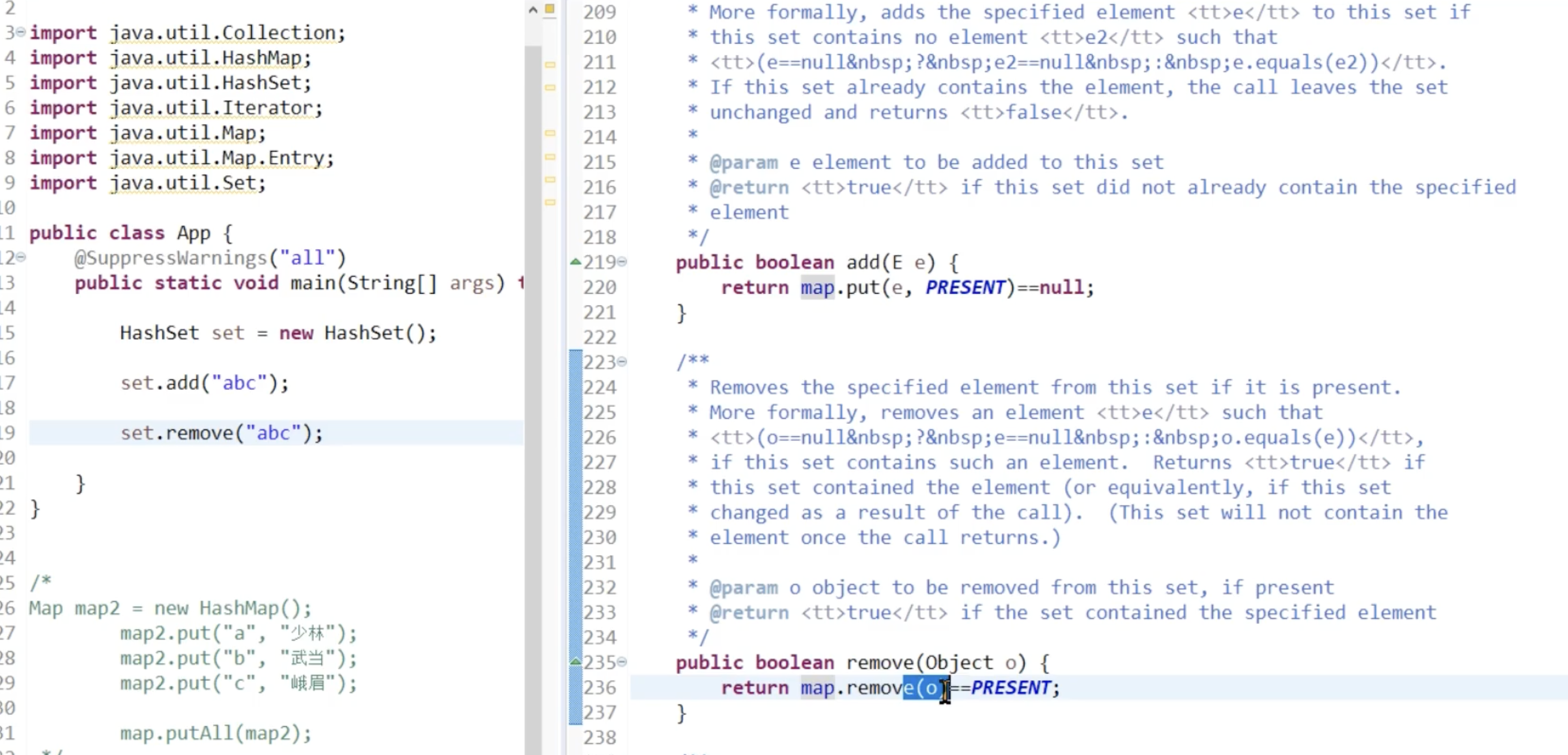
对象的比较

假设有一个Person类,包含name和age属性,并希望按年龄从小到大排序。
1 | |
在这里,compareTo方法根据age进行比较:
- 若当前对象
age小于参数对象age,则返回负数; - 若相等,返回0;
- 若大于,返回正数。
使用示例
可以使用Collections.sort对Person对象的列表进行排序:
1 | |
这就是面对扩展开发,修改关闭,TreeSet的作者留了,Comparator的接口,
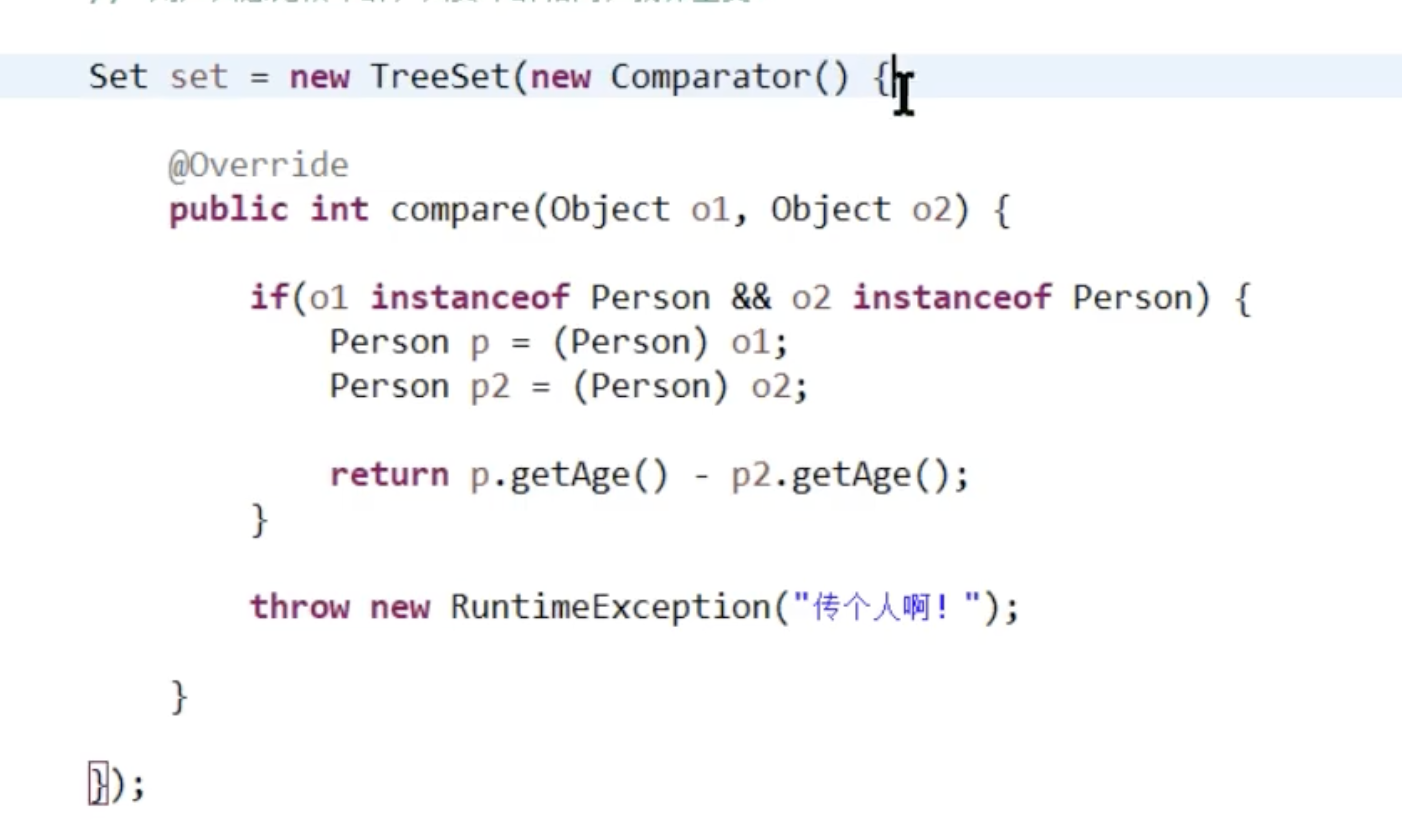
例如按照字符串长度比较
1 | |
为什么要使用迭代器

集合工具类
这个是只读集合
1 | |
可以这样做
1 | |
如果要交换集合的两个值?
1 | |
For加强
只有实现了Iterator的类才可以使用For加强循环,原来迭代器要实现hasNext和next的方法
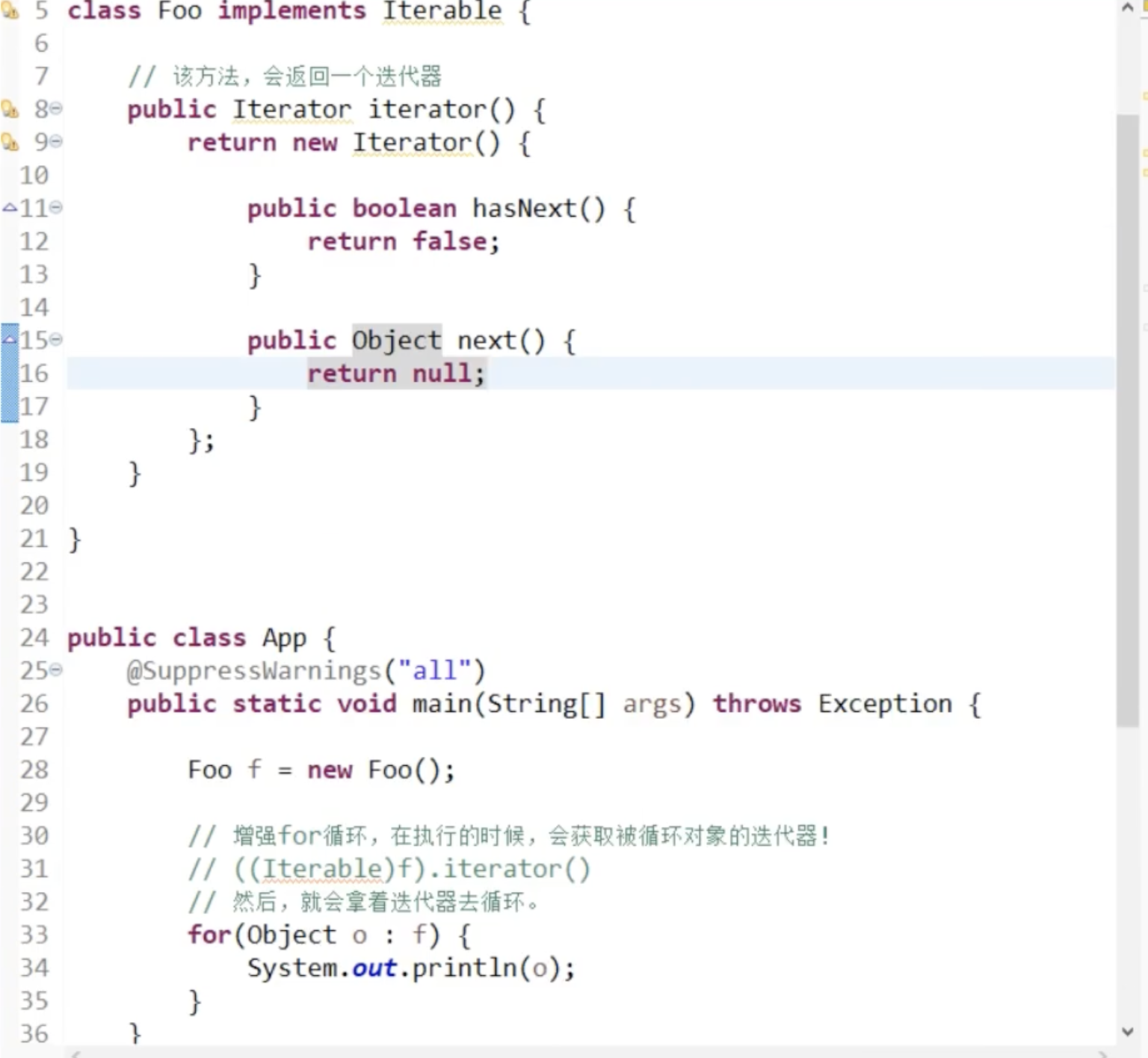
可变参数
可变参数就是类型后面加… 本质就是数组,可变参数必须放在最后面,因为不然有歧义,放前面,不知道第几个参数是第二个行参
反射

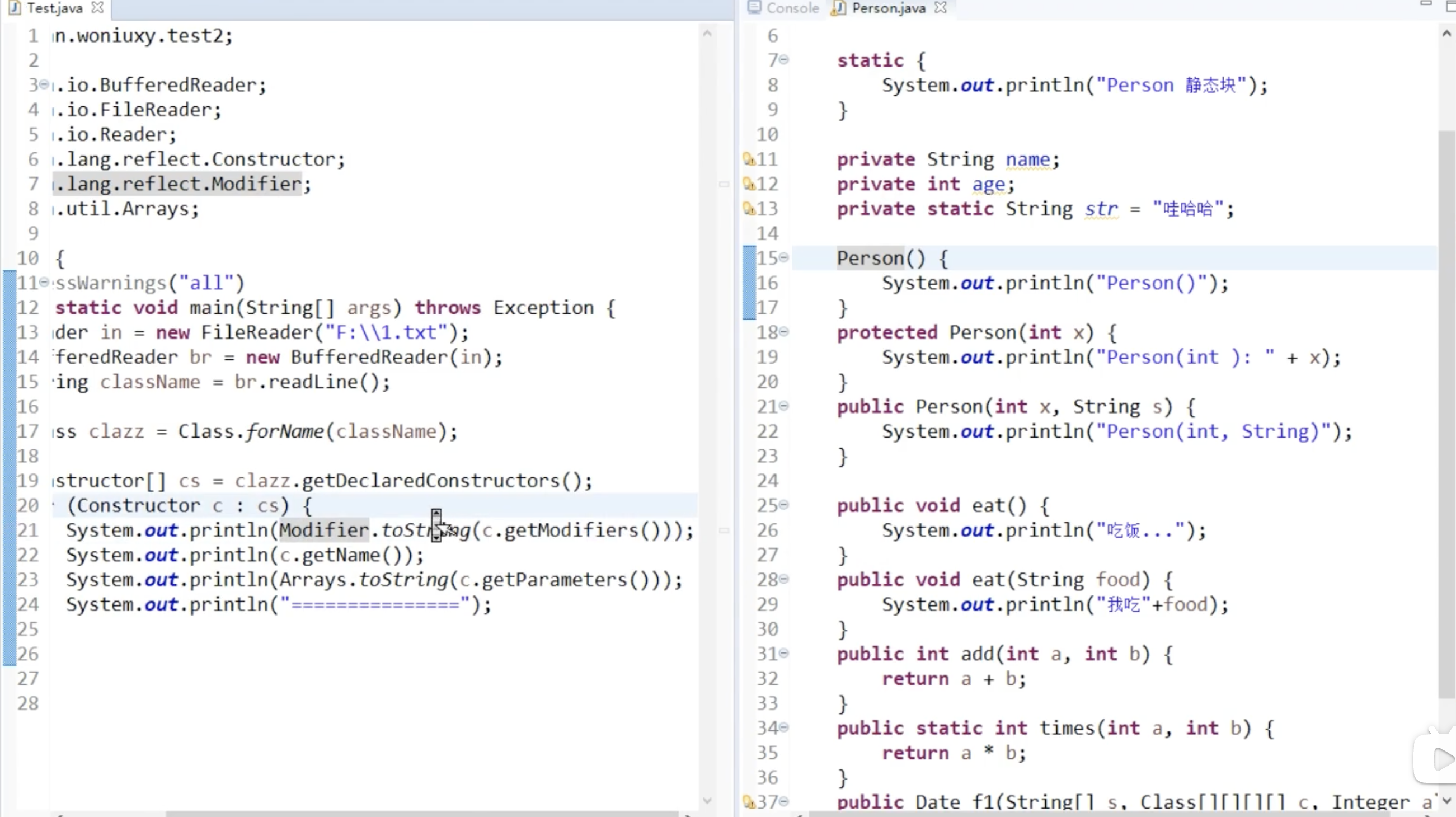
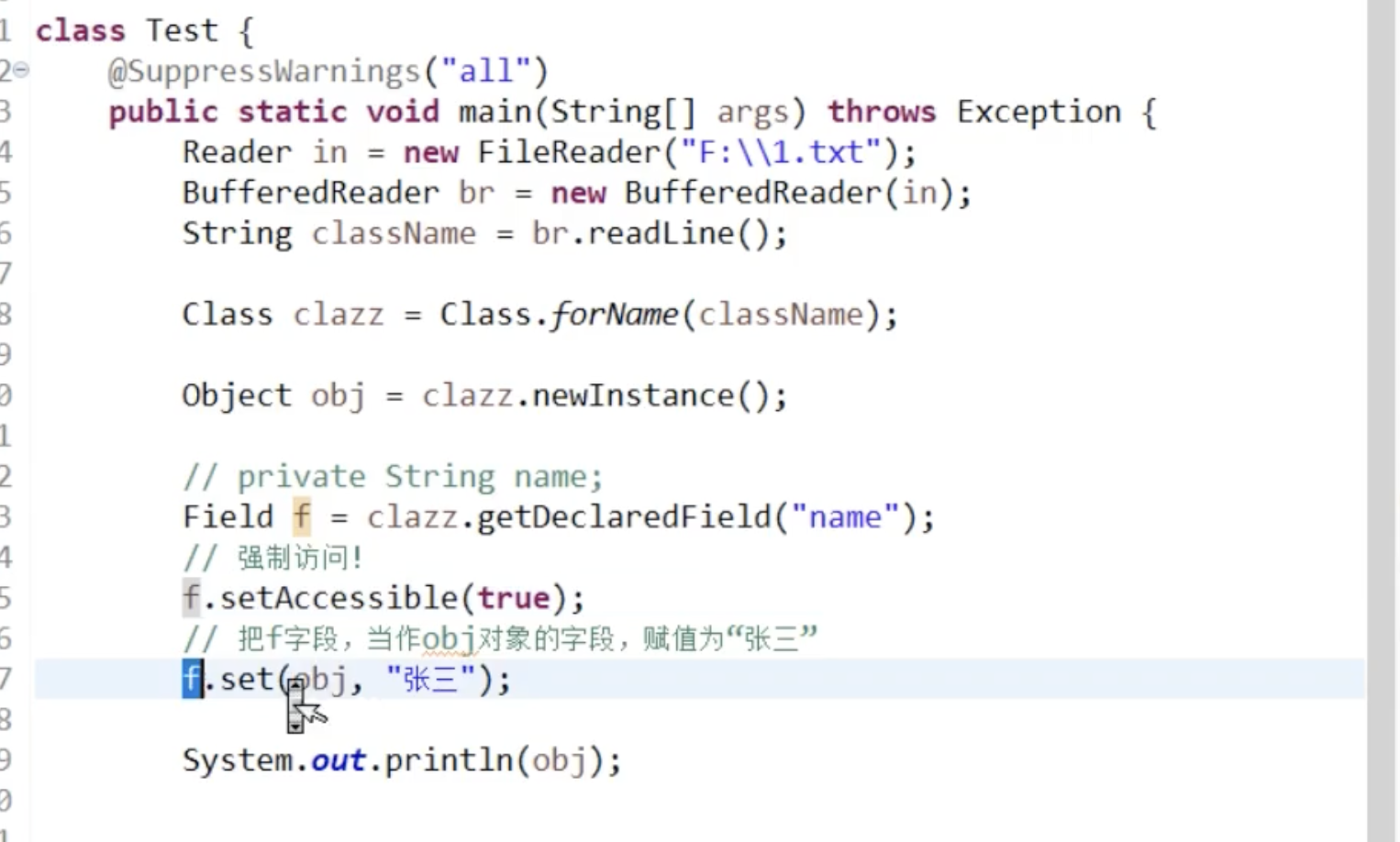
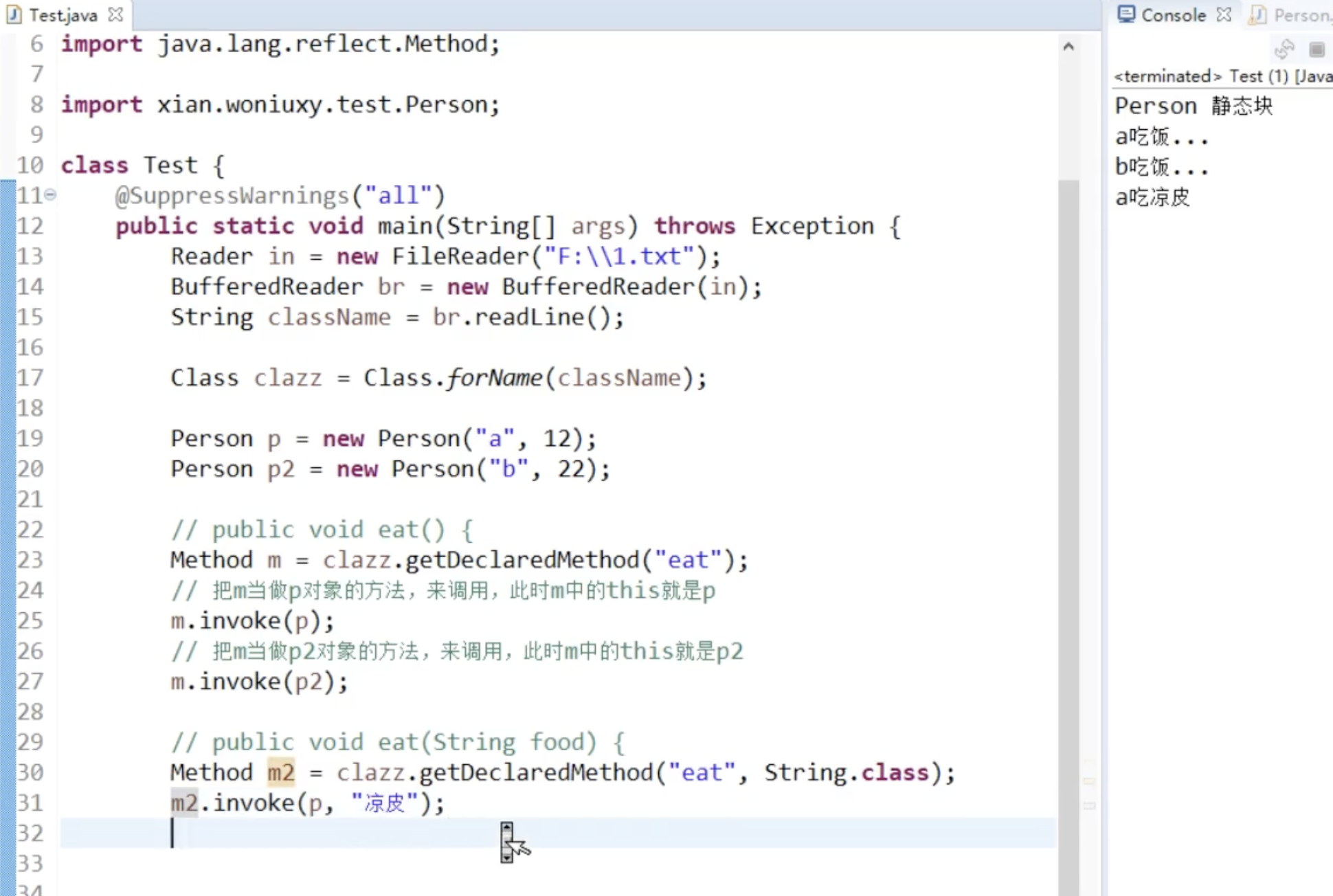
反射可以无视private
注解
用@interface定义注解
1 | |